Redo Log
MySQL 版本: 8.0.15
数据库系统在运行期间, 对于一个事务中的每一个 SQL 操作都不是瞬时能完成的. 当操作涉及数据的修改时, 意味着数据的一致性状态在发生变迁. 为了保证数据变化过程中的原子性, 需要记录每一次数据操作, 而 redo log 用来记录每次数据操作,用于 Crash 之后做 Recover 恢复操作,而每一条 redo log 都是由 mini-transaction 原子提交的.
在数据库运行期间, redo log 被要求先于数据页到达磁盘, 这样才能在系统故障发生后, 在系统恢复阶段保证事务的原子性.
redo log 的数据结构
这并不是单个 redo log 的数据结构,而是管理 redo log 元信息,redo log buffer 等操作的系统单元, 具体的对象为 log_sys.
include/log0types.h
struct alignas(INNOBASE_CACHE_LINE_SIZE) log_t {
atomic_sn_t sn; /* 当前 redo log 的 sn. */
aligned_array_pointer<byte, OS_FILE_LOG_BLOCK_SIZE> buf; /* redo log buffer 的内存区 */
Link_buf<lsn_t> recent_written; /* 解决并发插入 redo log buffer 后刷入 ib_logfile 存在空洞的问题. */
Link_buf<lsn_t> recent_closed; /* 解决并发插入 flush_list 后确认安全的 checkpoint_lsn 的问题. */
atomic_lsn_t write_lsn; /* write_lsn 之前的数据已经写入系统的 Page Cache, 但不保证已经Flush. */
atomic_lsn_t flushed_to_disk_lsn; /* 已经被 flush 到磁盘的 redo log LSN. */
size_t buf_size; /* redo log buffer 缓冲区的大小. */
lsn_t available_for_checkpoint_lsn; /* 在此 LSN 之前的所有被添加到 Buffer Pool 的 Flush List 的数据 Page 已经被 flsuh, 下一次checkpoint可以打在这个 LSN. */
lsn_t requested_checkpoint_lsn; /* 当前要求进行 checkpoint 的 lsn. */
atomic_lsn_t last_checkpoint_lsn; /* 当前的 checkpoint 的 lsn. */
uint32_t write_ahead_buf_size; /* write ahead 的 buffer 大小. */
lsn_t current_file_lsn; /* 当前 redo log 文件的 LSN 位置. */
uint64_t current_file_real_offset; /* 当前 ib_logfile 文件写入的 offset. */
uint64_t current_file_end_offset; /* 当前 ib_logfile 文件末尾的 offset. */
uint64_t file_size; /* 当前 ib_logfile 的文件大小. */
}mini-transaction
mini-transaction 具体流程
mtr_t mtr
mtr.start()
/* ... */
/* 写入数据至 mini-transaction 的 m_log. */
/* ... */
mtr.commit()mini-transaction 的数据结构
struct mtr_t {
/* mtr_t 内嵌一个结构体Impl. */
struct Impl {
mtr_buf_t m_memo; /* 一个被加锁的对象以及它加的锁. */
mtr_buf_t m_log; /* mini-transaction 的 log. */
bool m_made_dirty; /* 是否修改了 Buffer Pool 中的Page为脏页. */
bool m_modifications; /* 是否修改了 Buffer Pool 中的Page. */
ib_uint32_t m_n_log_recs; /* 该 mini-transaction 包含多少条log. */
mtr_log_t m_log_mode; /* mini-transaction 的操作模式(MTR_LOG_ALL, MTR_LOG_NO_REDO,MTR_LOG_NONE). */
mtr_state_t m_state; /* mini-transaction 的状态: MTR_STATE_INIT, MTR_STATE_ACTIVE, MTR_STATE_COMMITTING, MTR_STATE_COMMITTED. */
}
}其中 m_memo 中元素是 mtr_memo_slot_t, 记录加锁的对象和加锁的类型.
/** mini-transaction memo stack slot. */
struct mtr_memo_slot_t {
void *object; /* 加锁的对象. */
ulint type; /* 持有的锁类型,W or R. */
};mini-transaction 的start()
/** 启动一个 mini-transaction. */
@param sync true if it is a synchronous mini-transaction
@param read_only true if read only mini-transaction */
void mtr_t::start(bool sync, bool read_only) {
UNIV_MEM_INVALID(this, sizeof(*this));
UNIV_MEM_INVALID(&m_impl, sizeof(m_impl));
m_sync = sync;
m_commit_lsn = 0;
new (&m_impl.m_log) mtr_buf_t(); /* 记录 redo log 的 mtr 本地 Buffer. */
new (&m_impl.m_memo) mtr_buf_t();
/* 初始化 mini-transaction 字段. */
m_impl.m_mtr = this;
m_impl.m_log_mode = MTR_LOG_ALL;
m_impl.m_inside_ibuf = false;
m_impl.m_modifications = false;
m_impl.m_made_dirty = false;
m_impl.m_n_log_recs = 0;
m_impl.m_state = MTR_STATE_ACTIVE;
m_impl.m_flush_observer = NULL;
ut_d(m_impl.m_magic_n = MTR_MAGIC_N);
}不同的 mini-transaction 如何互斥?
在操作数据前,会根据锁类型,加不同类型的锁,之后将 object 和锁类型存入 m_memo:
mtr_memo_push(mtr, object, type);mini transaction commit 完成之后调用 release_latches(RELEASE_ALL) 将数据上的锁释放.
mini-transaction 插入数据
-
byte *mlog_open(mtr_t *mtr, ulint size): 打开mtr的m_log -
mlog_write_initial_log_record_low()函数向m_log中写入type,space id,page no,并增加m_n_log_recs的数量 -
mtr->get_log()->push()按不同的类型写数据 -
mlog_close(): 更新 m_log 中的位置
mini-transaction 的 commit 过程
commit 过程将 mini-transaction 的 m_log 数据拷贝到 redo log buffer 中, m_state 设置为 MTR_STATE_COMMITTING 后,具体流程是调用 mtr_t::Command::execute():
mtr_t::Command::execute()
-
prepare_write(): 根据 mtr 的类型m_impl->m_log_mode, 计算 redo log 的长度. 假如 redo log 记录数目n_recs为 1 时,设置Flag 为MLOG_SINGLE_REC_FLAG, log记录不止一条时,Flag置为MLOG_MULTI_REC_END. -
假如 redo log 的长度不为0时,
log_buffer_reserve():-
自增
log_sys中的全局sn, 由sn_lock锁保护.sn是一个全局维护的递增序列号, 具体含义是不包括 redo log Block 头部和尾部的序列号. -
获得 handler,计算写入 redo log 的
start_lsn和end_lsn,即实际写入的数据大小,lsn代表包括LOG_BLOCK_HDR_SIZE和LOG_BLOCK_TRL_SIZE的 redo log 序号, 而 sn 仅考虑 redo log 数据内容部分. 转换关系如下:
constexpr inline lsn_t log_translate_sn_to_lsn(lsn_t sn) { return (sn / LOG_BLOCK_DATA_SIZE * OS_FILE_LOG_BLOCK_SIZE + sn % LOG_BLOCK_DATA_SIZE + LOG_BLOCK_HDR_SIZE); }-
假如需要扩展 redo log buffer 的空间长度, 即
end_lsn大于sn_limit_for_end.log_wait_for_space_after_reserving()会进行扩展以及一系列的参数检查. -
因为全局的 redo log buffer 是环形的,假如待写的 redo log 长度超过了目前 redo log buffer 的剩余空闲长度则会出现回环后的覆盖写的问题,所以需要
log_wait_for_space_in_log_buf(log, start_sn)触发写入部分长度的 redo log, 以确保这条 redo log 能完整的写入 redo log buffer,而且回环后不会覆盖尚未写入磁盘的 redo log.void log_wait_for_space_in_log_buf(log_t &log, sn_t end_sn) { lsn_t lsn; Wait_stats wait_stats; /* 当前已经写入文件的 sn.*/ const sn_t write_sn = log_translate_lsn_to_sn(log.write_lsn.load()); LOG_SYNC_POINT("log_wait_for_space_in_buf_middle"); /* redo log buffer 的长度转换为 sn 后的长度. (去掉 Header 和 tailer). */ const sn_t buf_size_sn = log.buf_size_sn.load(); if (end_sn + OS_FILE_LOG_BLOCK_SIZE <= write_sn + buf_size_sn) { return; } /* We preserve this counter for backward compatibility with 5.7. */ srv_stats.log_waits.inc(); lsn = log_translate_sn_to_lsn(end_sn + OS_FILE_LOG_BLOCK_SIZE - buf_size_sn); /* 等待 lsn 之前的 redo log 被写入. */ wait_stats = log_write_up_to(log, lsn, false); MONITOR_INC_WAIT_STATS(MONITOR_LOG_ON_BUFFER_SPACE_, wait_stats); ut_a(end_sn + OS_FILE_LOG_BLOCK_SIZE <= log_translate_lsn_to_sn(log.write_lsn.load()) + buf_size_sn); } -
这里可能会和 redo log buffer 允许空洞产生歧义,需要注意的是 redo log buffer 允许的空洞是
write_lsn之后的 redo log buffer 允许空洞,现在的情况是因为一条 redo log 的长度超过了 redo log buffer 的剩余长度需要回环,所以在此之前的 redo log 必须保证写入完成. -
log_write_up_to()需要 wait 在log_t中的write_events. 当log.write_lsn.load() >= lsn, 即对应于 redo log buffer 中的 slot 的 redo log 已经完成了写入并被唤醒. -
对于长度大于当前整个 redo log buffer 的 redo log, 需要调用
log_buffer_resize_low()来 Resize 设置 redo log buffer 的长度, 过程是释放旧长度的 redo log buffer 空间,重新分配新长度的 redo log buffer 空间,并且重新拷贝 redo log 内容. -
对m_log中的每一个 512 字节的 Block 调用
mtr_write_log_t()(需要注意的是mtr_write_log_t()是运算符()的重载)-
log_buffer_write()使用memcpy()写 redo log buffer. -
log_buffer_write_completed()更新log_t中的recent_written,即(start_lsn,end_lsn)组成的list.
-
-
调用
add_dirty_blocks_to_flush_list()将产生的脏页 dirty page 插入 Buffer Pool 中的flush_list.
-
-
log_wait_for_space_in_log_recent_closed()查看recent_closed链表是否存在符合该 redo log 规则的 space. -
假如 redo log 的长度为0时:
- 直接调用
add_dirty_blocks_to_flush_list().
- 直接调用
-
add_dirty_blocks_to_flush_list():-
假如产生了 redo log,则将数据页的
newest_modification修改为end_lsn. -
假如该 Block 是第一次被修改,就需要插入 Buffer Pool 的
flush_list. 将涉及修改的数据页添加到 Buffer Pool 的flush_list(buf_flush_insert_into_flush_list()).(利用block->page.oldest_modification来判断是否为第一次修改)
-
-
log_buffer_close(): 将对应的 Page 插入 Buffer Pool 中的flush_list后更新log_t中的recent_closed链表. -
release_resources()释放资源, 将m_state置为MTR_STATE_COMMITTED
redo log buffer
redo log buffer 是一段内存区域用来存放需要写入 ib_logfile 的数据. redo log buffer 的大小 buf_size 可以通过 innodb_log_buffer_size 来控制, 默认16MB.
redo log buffer 的 resize 过程
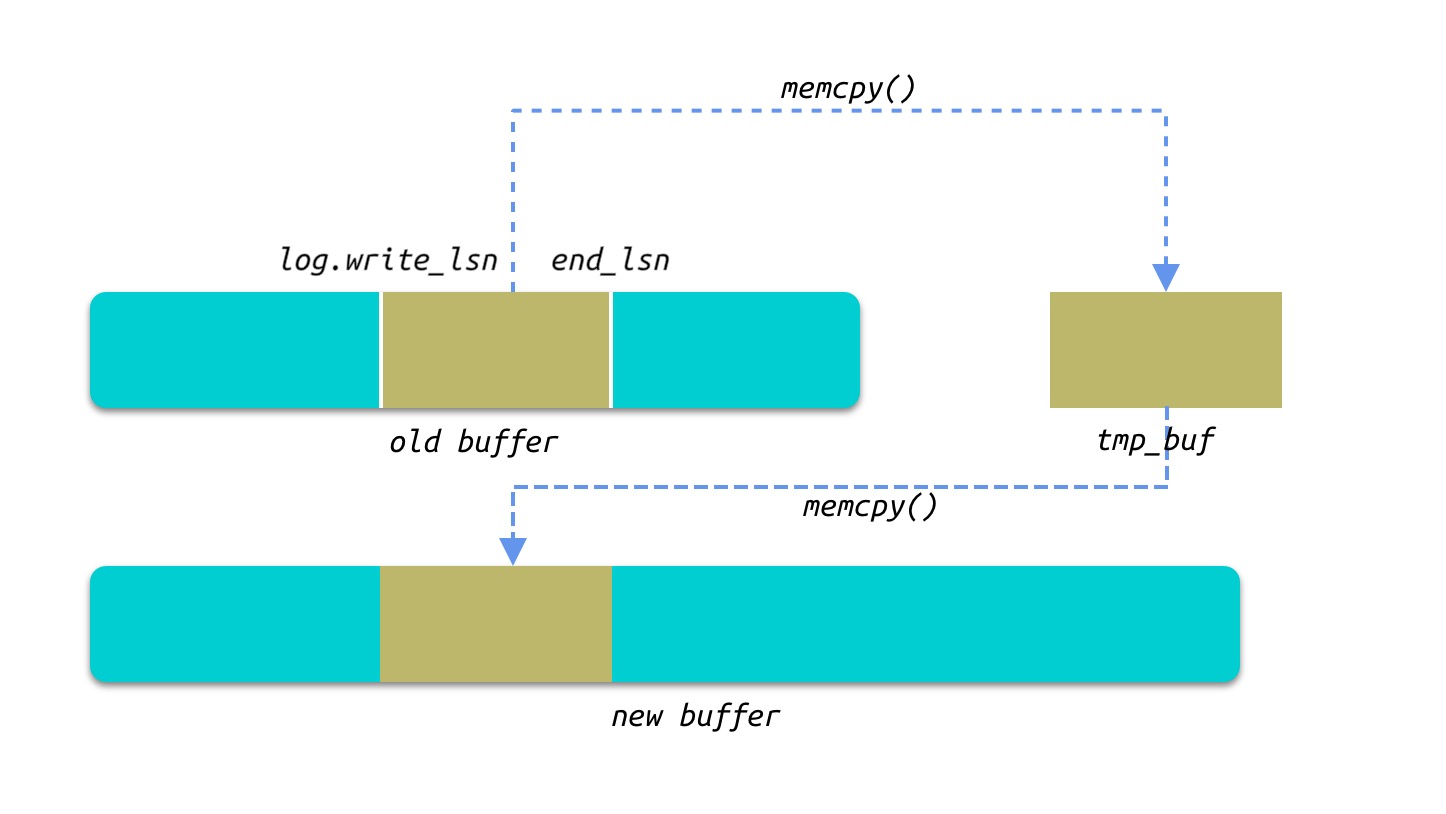
redo log buffer 是我们通常所说的回环 Buffer, 而在 Resize 的过程中将 log.write_lsn 和 end_lsn 直接的 redo log 拷贝至一个临时的 Buffer,然后新建一个 new_size 的 Buffer, 将 tmp_buf 的数据原路拷贝.
redo log 模块的线程
log_writer
完成 redo log buffer 的写入, 即写入 ib_logfile 文件. (log/log0write.cc)
-
log_writer线程 wait 在一个限定的 condition,即直到满足log.write_lsn.load() < log.recent_written.tail()时调用log_writer_write_buffer()进行 redo 写入. 指定的condition函数会递增log.recent_written.tail.log.write_lsn代表当前写入的 lsn 位置,log.recent_written.tail()返回的是 redo log buffer 中最大的不存在空洞的 lsn. -
具体写入流程在
log_files_write_buffer(), 首先计算写入在文件的真实偏移:
/* start_lsn为该次写入的起始lsn */
const auto real_offset =
log.current_file_real_offset + (start_lsn - log.current_file_lsn);
```
-
计算目前的
ib_logfile文件是否有足够的空间满足该条 redo log 的写入:-
假如目前的
ib_logfile已经写满,则需要调用start_next_file()直接切换下一个文件. -
假如目前的
ib_logfile还拥有空闲的空间,则需要将 redo log 分两次写入,但本次写入仅填充目前的ib_logfile的剩余空间.
-
-
MySQL8.0 在写入 redo log 的过程中引入了
write ahead buffer避免小于 512 bytes 的 IO 造成read on write现象: -
write_blocks()来调用fil_redo_io()来完成文件写入(写入操作系统的Page Cache), 每次写入都是512 Bytes对齐(OS_FILE_LOG_BLOCK_SIZE) -
更新
log.write_lsn -
调用
notify_about_advanced_write_lsn()唤醒对应 slot 正在 wait 的线程, 这里其实就是 mini-transaction 的 commit 阶段写入 redo log buffer 中,需要等待log.write_lsn.load() >= lsn的部分. -
唤醒 redo log 的 Flusher 线程(
os_event_set(log.flusher_event))
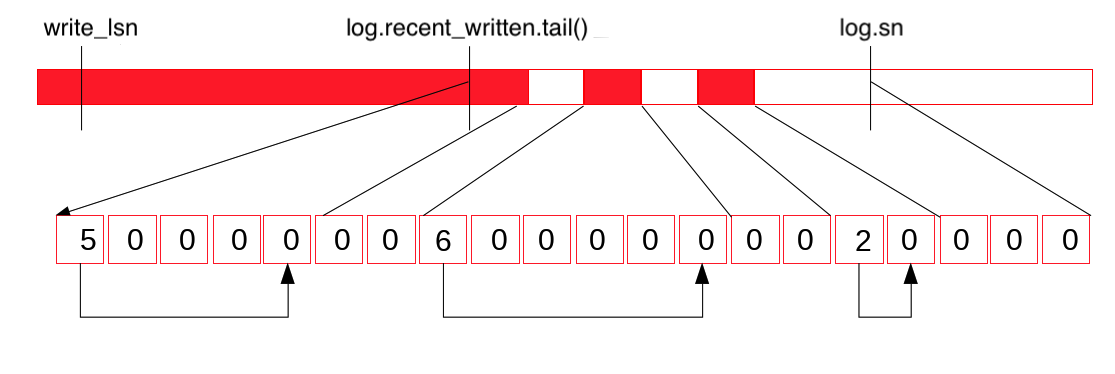
上图表示 redo log buffer,这里需要考虑的是 log.recent_written.tail() 也是由 log_writer 线程来更新的,因为 mtr 的 commit 过程根据 lsn 计算拷贝至 redo log buffer 的位置,这里是允许空洞的,所以为了保证 Flush 至文件时能 Batch 无空洞写入,这里使用 log.recent_written 的 tail 来保证在 tail 之前的 redo log buffer 是不存在空洞的.
write_ahead_buffer
引入 write_ahead_buffer 的目的是为了避免小 IO 造成的 read-on-write. Linux 下的写操作会先将对应的文件内容读入 Page Cache, 修改完成后,通过 fsync 来决定是否持久化至文件. 为了避免读取至 Page Cache 的这次 IO, InnoDB 使用 write-ahead buffer 来解决这个问题,这个策略的前提条件是: a.写入的目的偏移是 Page 对齐, b.写入的大小是 Page 大小的的整数倍. 在这样的前提条件下, 文件系统可以避免一次 IO 读.
write-ahead buffer 的核心代码如下: 通过 compute_how_much_to_write() 首先判断是否使用 write_ahead_buffer:
/* write_from_log_buffer 为 bool 变量,记录后续 log_writer 的写操作需要将 redo log 拷贝至
* write_ahead_buffer. 这次首先判断对于大于 OS_FILE_LOG_BLOCK_SIZE (512字节) 的 redo log
* 都是直接从 redo log buffer 写入,而不使用 write_ahead buffer. */
write_from_log_buffer = write_size >= OS_FILE_LOG_BLOCK_SIZE;
/* ... */
if (!current_write_ahead_enough(log, real_offset, write_size)) {
/* 假如 write_ahead_buffer 的剩余空间不满足存放 write_size 大小的 redo log. */
if (!current_write_ahead_enough(log, real_offset, 1)) {
/* 经过判断 write_ahead_buffer 已经没有任何剩余空间(1 个字节的剩余空间都没有了). */
/* 计算开启下一个 write_ahead_buffer 的结束偏移位置 */
const auto next_wa = compute_next_write_ahead_end(real_offset);
/* Note. 这里有一个隐藏的假设:
* a. 当某次写 IO 的目的偏移地址是与 log_sys->write_ahead_buf 当前覆盖范围
* 的结束地址对齐时,则假定该次写 IO 目标区域在内存没有对应的 Page Cache,需
* 要重新执行一次 write ahead 操作.
*
* b. 当执行一次 write ahead 逻辑后,在接下来的一段时间内,该区域对应的 Page
* Cache 会保存在内存中,后续对当前 write ahead buffer 可以覆盖的文件区域的
* 写 IO,都可以命中这些 Page Cache, 从而避免额外的读 IO 开销. */
if (!write_ahead_enough(next_wa, real_offset, write_size)) {
/* 下一个 write_ahead_buffer 仍然不满足存放 write_size 大小的 redo log,
* 即直接从 redo log buffer 写入,无需拷入 write_ahead_buffer,但大小被
* 限制为不能超过 srv_log_write_ahead_size,
* 所以 redo log 的写入最大也就是写 srv_log_write_ahead_size. */
ut_a(write_from_log_buffer);
/* 需要注意的是,这里不经过 write_ahead_buffer 的直接写入,但 real_offset 是通过
log.write_lsn 进行 OS_FILE_LOG_BLOCK_SIZE 对齐计算的,所以 redo log buffer 的直接
写入依然是 OS_FILE_LOG_BLOCK_SIZE 对齐的. */
write_size = next_wa - real_offset;
ut_a((real_offset + write_size) % srv_log_write_ahead_size == 0);
ut_a(write_size % OS_FILE_LOG_BLOCK_SIZE == 0);
} else {
/* 下一个开启的 write_ahead_buffer 满足预写 write_size 大小的 redo log. */
write_from_log_buffer = false;
}
} else {
/* 当前的 write_ahead_buffer 存在剩余空间,则先使用剩余空间大小的 write ahead buffer
* 完成部分 redo log 写入 */
write_size = static_cast<size_t>(log.write_ahead_end_offset - real_offset);
ut_a(write_size >= OS_FILE_LOG_BLOCK_SIZE);
ut_a(write_size % OS_FILE_LOG_BLOCK_SIZE == 0);
}
} else {
if (write_from_log_buffer) {
/* 512 字节向下取整对齐写入. */
/* 这个路径代表当前的 write_ahead buffer 已经能 cover 此次写入, 所以直接
* 512 字节对齐写入(写入对应的 Page 已经存在 Page Cache 中). */
write_size = ut_uint64_align_down(write_size, OS_FILE_LOG_BLOCK_SIZE);
}
}
/* 总结写 redo log 的各种情况:
* 1. 对于写入 redo log 小于 OS_FILE_LOG_BLOCK_SIZE 的情况, 并且满足 write_ahead
* buffer 的写入(无论是当前的 write_ahead 还是下次重新开辟 write_ahead buffer 的
* 写入, 都通过 log_buffer->write_ahead buffer 的方式写入.
*
* 2. 对于写入 redo log 大于等于 OS_FILE_LOG_BLOCK_SIZE 的情况, 并且满足 write_ahead
* buffer 的写入(无论是当前的 write_ahead 还是下次重新开辟 write_ahead buffer 的
* 写入, 都通过 log_buffer->write_ahead buffer 的方式写入.
*
* 3. 对于写入 redo log 大于等于 OS_FILE_LOG_BLOCK_SIZE 的情况,但是不满足 write_ahead
* buffer 的写入(无论是当前的 write_ahead buffer 还是下次重新开辟 write_ahead buffer
* 的写入), 需要通过 log_buffer 直接写入的方式完成. */
/* 返回此次需要写入的 redo log 长度. */
return (write_size);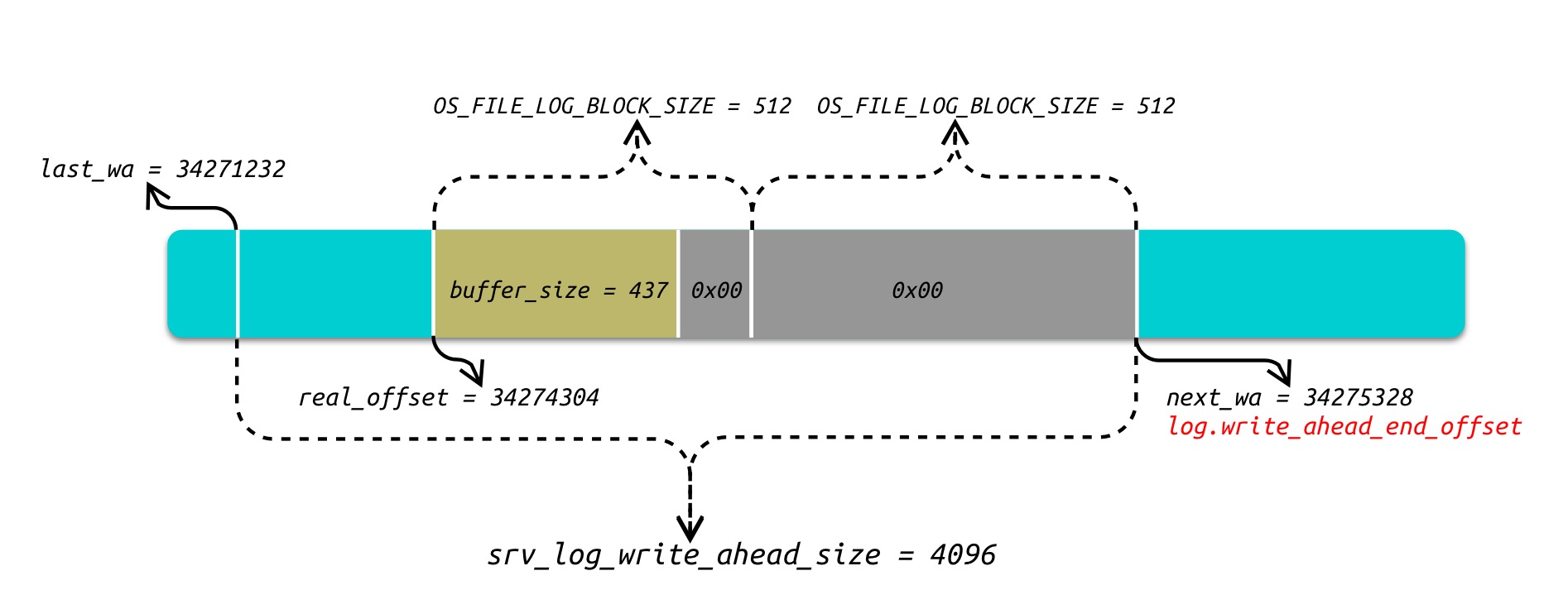
上图举例 write_ahead_buffer 的一次写入过程: 假如需要在 real_offset 即 34274304 位置开始写入 buffer_size 为 437 大小的数据,假定目前 write_ahead_buffer 已经被上一次的写入写满,所以本次写入需要重新滑动.
-
将
real_offset向下取整srv_log_write_ahead_size求得last_wa和next_wa的位置, 即last_wa和next_wa的区间为本次的write_ahead_buffer. -
将数据
buffer后面的部分均以0x00填充直到next_wa, 即本次写入的数据为437 + 75 + 512 = 1024大小。75 + 512的部分为log_writer的预写(write ahead). -
write_ahead_buffer重新滑动后,写入完成后会更新log.write_ahead_end_offset:
static inline void update_current_write_ahead(log_t &log, uint64_t real_offset, size_t write_size) {
/* 假如 write_ahead_buffer 经过了滑动, write_size则为数据 + 0x00 预写的大小 */
const auto end = real_offset + write_size;
if (end > log.write_ahead_end_offset) {
log.write_ahead_end_offset = ut_uint64_align_down(end, srv_log_write_ahead_size);
}
}所以 log_writer 线程的每次写入都是 OS_FILE_LOG_BLOCK_SIZE 对齐写入,并且大小不会超过 srv_log_write_ahead_size.
log_flusher
将 redo log buffer 中的日志进行 Flush, 这里进行的是 redo log 的刷脏,与数据脏页的 Flush 无关,数据脏页的 Flush 由 Buffer Pool 刷脏线程处理.
-
log_fluser根据srv_flush_log_at_trx_commit来选择不同的wait方式:- 假如
srv_flush_log_at_trx_commit=1即
os_event_wait_time_low(log.flusher_event, flush_every_us - time_elapsed_us, 0);
* 否则: > ```c++ const auto wait_stats = os_event_wait_for(log.flusher_event, max_spins, srv_log_flusher_timeout, stop_condition); - 假如
-
假如
last_flush_lsn < log.write_lsn.load(),即需要进行刷盘. -
fil_system->flush_file_redo()进行文件刷盘. -
更新
log.flushed_to_disk_lsn. -
唤醒 wait 在该
slot[last_flush_lsn, flush_up_to_lsn]的用户线程.
innodb_flush_log_at_trx_commit 的取值范围是: 1, 2, 0.
innodb_flush_log_at_trx_commit = 1: InnoDB 将在每次事务提交时将 Redo Log Buffer 的数据更新到文件系统 OS Buffer 中, 并调用文件系统的 Flush 操作将数据缓存更新至磁盘中. innodb_flush_log_at_trx_commit = 2: InnoDB 将在每次事务提交时仅仅需要将 Redo Log Buffer 的数据更新到文件系统 OS Buffer 中, 每秒将文件系统中的缓存 Redo Log 写入磁盘一次. innodb_flush_log_at_trx_commit = 0: InnoDB 每秒钟将 Redo Log Buffer 的 Redo Log 写入到磁盘.
log_closer
更新 log.recent_closed 的 tail.
log_checkpointer
进行 checkpoint 的线程
-
更新
available_for_checkpoint_lsn, 即目前可以安全进行 checkpoint 的lsn. -
扫描所有 Buffer Pool 的
flush_list,获取最旧的一条 redo log 的 lsn(bpage = UT_LIST_GET_LAST(buf_pool->flush_list). 这里最旧的 lsn 并不代表 lsn 是最小的,因为插入flush_list是允许并发插入的. -
flush_list中最旧的 lsn 减去recent_closed的长度,然后与上次 checkpoint 的 lsn 进行比较, 选较大的lsn_t lwm_lsn = (std::max(checkpoint_lsn, lsn - lag)). -
与
log.recent_closed.tail比较(const lsn_t dpa_lsn = log.recent_written.tail()),选较小的(lwm_lsn = std::min(lwm_lsn, dpa_lsn). -
与
log.flushed_to_disk_lsn比较,选较小的(std::min(lwm_lsn, flushed_lsn)). -
更新
log.available_for_checkpoint_lsn. -
计算
current_lsn, 与log.available_for_checkpoint_lsn比较,假如在此期间又有脏页被刷入flush list, 则一并进行预 Flush. 之后更新log.available_for_checkpoint_lsn. -
检查是否需要checkpoint
-
log_checkpoint(log)进行 checkpoint, 其中就是调用接口将 checkpoint 的信息写入指定的文件.
recent_written 与 recent_closed 的作用
recent_written
- MySQL 8.0 通过直接计算每一条 redo 在 redo log buffer 的 offset 来并发插入 redo log buffer, 所以这里是允许 redo log buffer 存在空洞的,而写入
ib_logfile不允许,所以利用recent_written.tail来保证在此 lsn 之前的 redo log buffer 是不存在空洞的,从而完成ib_logfile的完整写入.
recent_closed
- 为了能安全的进行 checkpoint, 需要选择一个数据已经被 Flush 的 redo log 的lsn, 因为可以并发的将脏页插入 Buffer Pool 中的
flush_list, 所以选择所有 Buffer Pool 的flush_list中头部最小的一个 Dirty Page 的 lsn, 再与log.recent_closed.tail()比对选择一个较小的 lsn, 可以认为是一个安全的checkpoint_lsn.log.recent_closed记录着并行插入flush_list的 Page lsn.
redo log 中 Record 的格式
MLOG_REC_INSERT 的 redo 格式

Q & A
- redo log 文件大小设置过小造成性能抖动?
假如 redo log 文件大小设置过小,会导致 redo log 文件的空闲空间不足, 造成频繁的 checkpoint, 而 checkpoint 的推进前提是对应 Buffer Pool 的脏页已经完全落盘,所以 redo log 的落盘会间接推动脏页的 Buffer Pool 的落盘, 从而加剧系统的 IO,可能造成性能抖动.