Linux 环境写文件如何稳定跑满磁盘 I/O 带宽?
准备
要求:
在限制内存的情况下,假定我们每次写入 4k 的数据,如何保证 kill -9 不丢数据的情况下,仍然稳定的跑满磁盘的 IO ?因为需要保证 kill -9 不丢数据,所以 fwrite() 就不在我们的考虑范围之内了. 又因为限制内存,所以直观的想法是直接 Direct IO, 但 Direct IO 能否跑满磁盘 IO 呢?
机器配置:
CPU: 64核 Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
磁盘: Intel Optane SSD
测试磁盘IO性能:
官方称读/写带宽是 2400/2000 MB/s, 我们利用 fio 来进行实测:
顺序读性能:
sudo fio --filename=test -iodepth=64 -ioengine=libaio --direct=1 --rw=read --bs=2m --size=2g --numjobs=4 --runtime=10 --group_reporting --name=test-read结果:
READ: bw=2566MiB/s (2691MB/s), 2566MiB/s-2566MiB/s (2691MB/s-2691MB/s), io=8192MiB (8590MB), run=3192-3192msec 顺序写性能:
sudo fio --filename=test -iodepth=64 -ioengine=libaio -direct=1 -rw=write -bs=1m -size=2g -numjobs=4 -runtime=20 -group_reporting -name=test-write结果:
WRITE: bw=2181MiB/s (2287MB/s), 2181MiB/s-2181MiB/s (2287MB/s-2287MB/s), io=8192MiB (8590MB), run=3756-3756msec实测读写带宽: 2566/2181 MB/s
实验一: Buffer IO 写入
因为是限制内存,所以 Buffer IO 不在我们的考虑范围内,但是我们先来测试一下 Buffer IO 的具体性能到底如何? 我们使用最简单的方法,因为我们的 CPU 核数是64,所以直接 64 线程单次 4K 字节 Buffer IO 写入, 即通过操作系统的 Page Cache 的策略来缓存,刷盘:
代码片段: 完整代码
static char data[4096] attribute((aligned(4096))) = {'a'};
void writer(int index) {
std::string fname = "data" + std::to_string(index);
int data_fd = ::open(fname.c_str(), O_RDWR | O_CREAT | O_APPEND, 0645);
for (int32_t i = 0; i < 1000000; i++) {
::write(data_fd, data, 4096);
}
close(data_fd);
}
int main() {
std::vectorstd::thread threads;
for(int i = 0; i < 64; i++) {
std::thread worker(writer, i);
threads.push_back(std::move(worker));
}
for (int i = 0; i < 64; i++) {
threads[i].join();
}
return 0;
}
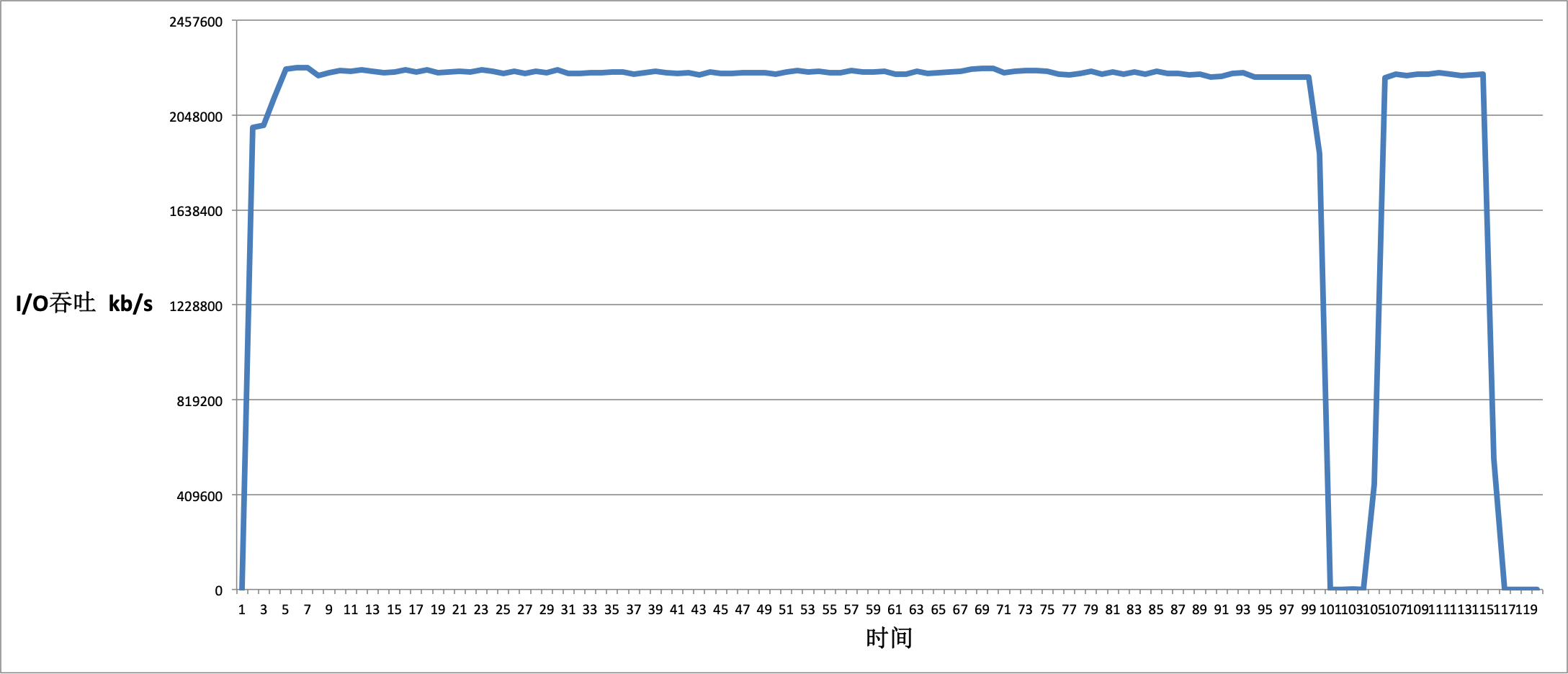
我们通过 O_APPEND 单次 4k 追加写入,之后通过 vmstat 来保留 120s 的写入带宽:
vmstat 1 120 > buffer_io 经过最后的测试数据整理,我们发现 Buffer IO 的性能基本能稳定跑满带宽, 其中只有一次 I/O 抖动:
实验二: 4K 单次 Direct IO 写入
Buffer IO 利用 Page Cache 帮助我们缓存了大量的数据,必然提高了写入带宽,但假如在限制内存的情况下,Buffer IO 就不是正确的解决方案了,这次我们绕过 Page Cache, 直接 Direct IO 单次 4K 写入:
代码片段: 完整代码
唯一需要修改的地方就是在 open() 中加入 O_DIRECT 标志:
int data_fd = ::open(fname.c_str(), O_RDWR | O_CREAT | O_APPEND | O_DIRECT, 0645);通过 vmstat 获取写入带宽数据, 整理如下:
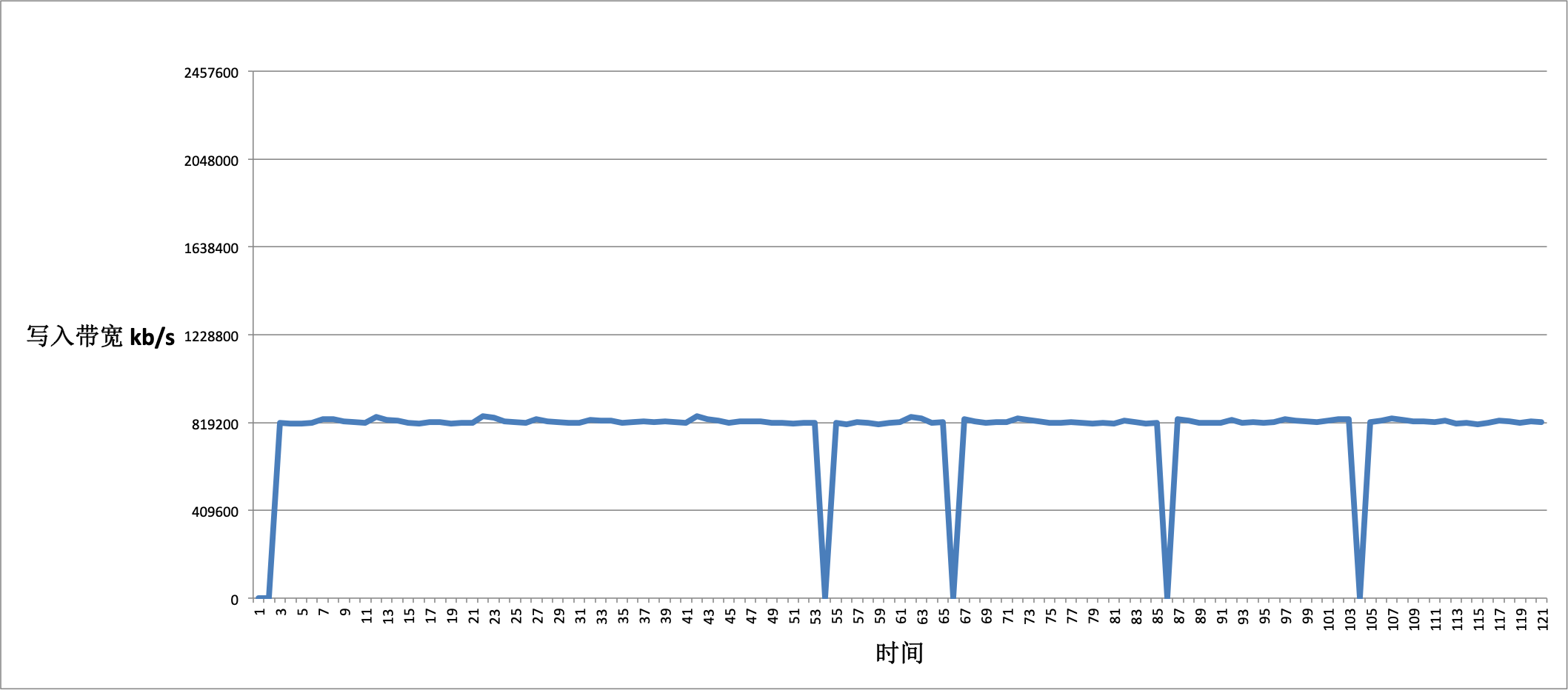
通过数据我们发现,单次4k的 Direct IO 写入无法跑满磁盘的I/O带宽,仅仅只有 800MB/S
实验三: mmap 写入
通过前面这两个实验我们发现,Buffer IO 是可以跑满磁盘 I/O 的,那我们可以尝试模拟 Buffer IO 的写入方式,使用较少的内存来达到 Buffer IO 的写入效果.
我们使用 mmap 来实现 Buffer IO 写入,通过限定的 Buffer Block 来模拟 Page Cache 的聚合效果, 实验中我们使用 memcpy 来完成数据拷贝,Buffer Block 我们设定为 4K * 4, 与 Direct IO 的不同,我们这次限定即 16KB 的单次写入:
代码片段: 完整代码
main() 函数不变,修改线程的 writer() 函数:
static char data[4096] attribute((aligned(4096))) = {'a'};
static int32_t map_size = 4096 * 4;
void MapRegion(int fd, uint64_t file_offset, char** base) {
void* ptr = mmap(nullptr, map_size, PROT_READ | PROT_WRITE,
MAP_SHARED,
fd,
file_offset);
if (unlikely(ptr == MAP_FAILED)) {
*base = nullptr;
return;
}
base = reinterpret_cast<char>(ptr);
}
void UnMapRegion(char* base) {
munmap(base, map_size);
}
void writer(int index) {
std::string fname = "data" + std::to_string(index);
char* base = nullptr;
char* cursor = nullptr;
uint64_t mmap_offset = 0, file_offset = 0;
int data_fd = ::open(fname.c_str(), O_RDWR | O_CREAT, 0645);
posix_fallocate(data_fd, 0, (4096UL * 1000000));
MapRegion(data_fd, 0, &base);
if (unlikely(base == nullptr)) {
return;
}
cursor = base;
file_offset += map_size;
for (int32_t i = 0; i < 1000000; i++) {
if (unlikely(mmap_offset >= map_size)) {
UnMapRegion(base);
MapRegion(data_fd, file_offset, &base);
if (unlikely(base == nullptr)) {
return;
}
cursor = base;
file_offset += map_size;
mmap_offset = 0;
}
memcpy(cursor, data, 4096);
cursor += 4096;
mmap_offset += 4096;
}
UnMapRegion(base);
close(data_fd);
}
我们通过 vmstat 来获取写入带宽数据,我们发现 mmap 的 16K 写入可以跑满磁盘带宽,但 I/O 抖动较大,无法形成类似于 Buffer IO 稳定的写入.
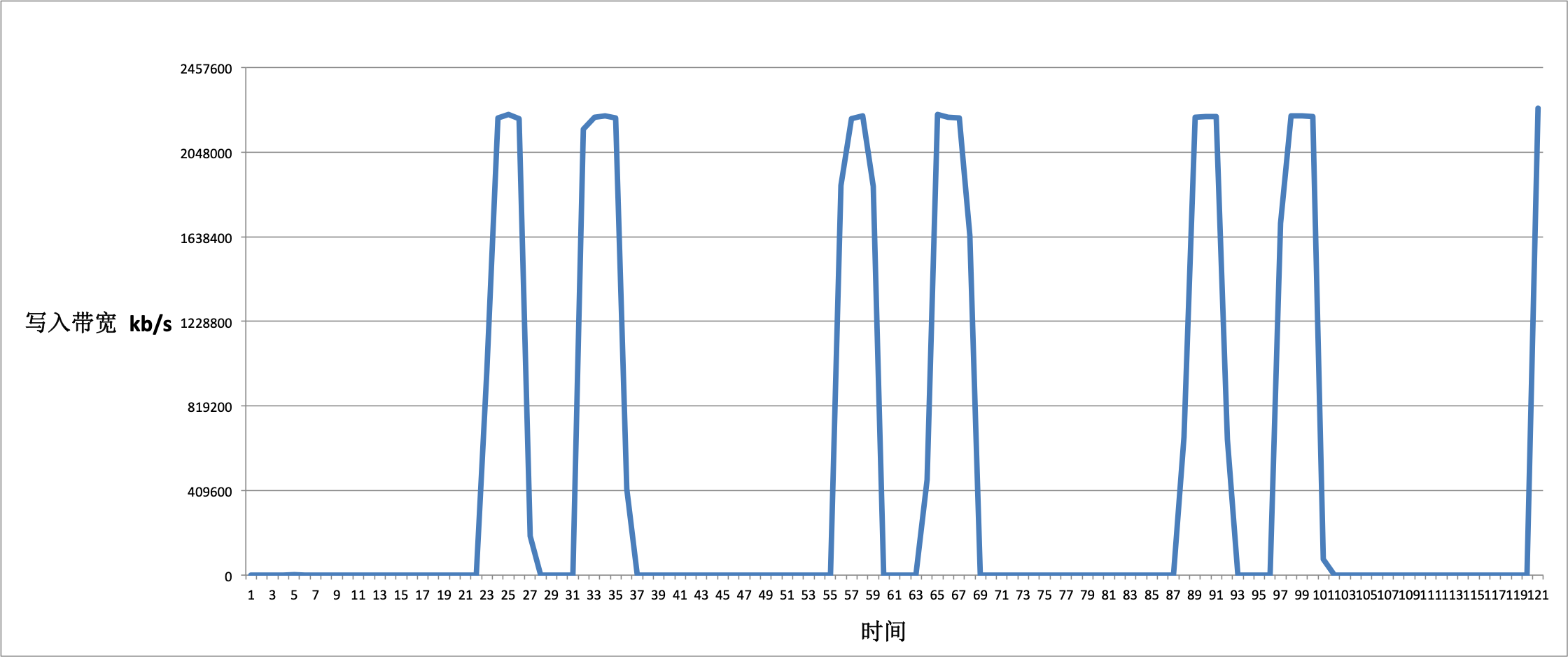
我们通过 perf 生成火焰图分析:
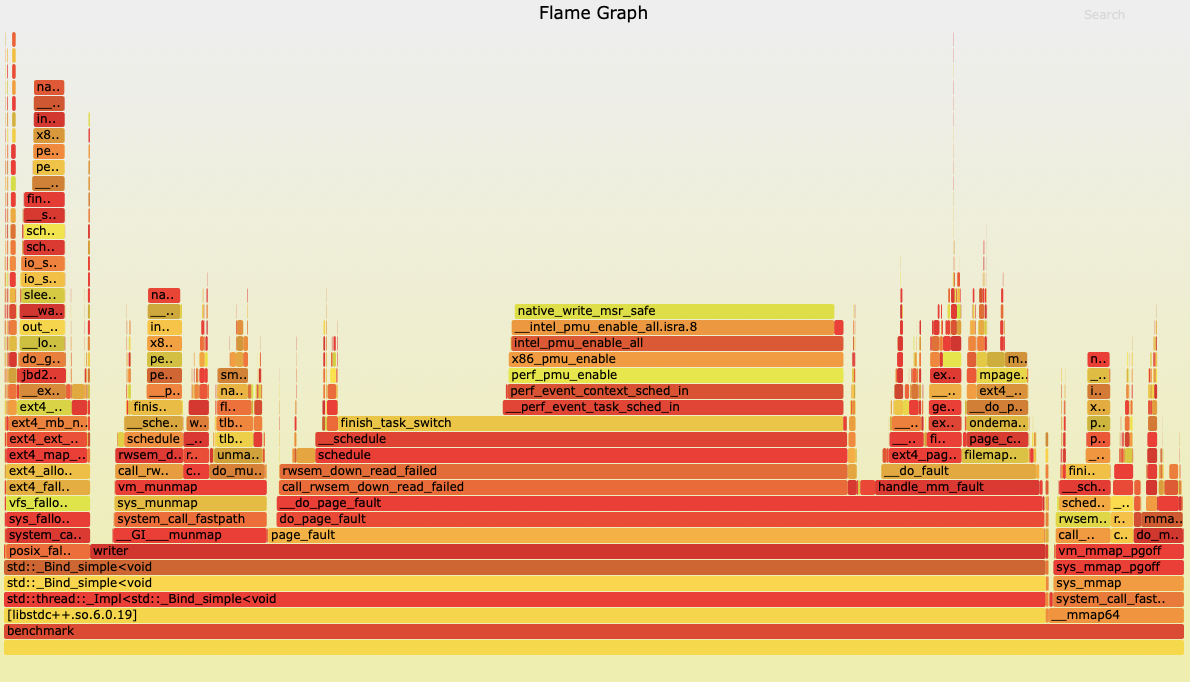
通过 pref 生成分析瓶颈时发现,写入 writer() 时触发了大量的 Page Fault, 即缺页中断,而 mmap() 本身的调用也有一定的消耗(mmap() 的源码分分析,我们实验三的思路是: 首先 fallocate 一个大文件,然后 mmap() 内存映射 16k 的 ‘Block’, memcpy() 写满之后,游标右移重新 mmap(),以此循环.
实验四: 改进的 mmap 写入
为了避免 mmap() 的开销,我们使用临时文件在写入之前 mmap() 映射,之后循环利用这 16K 的Block, 避免 mmap() 系统调用的开销:
代码片段: 完整代码
void MapRegion(int fd, uint64_t file_offset, char** base) {
void* ptr = mmap(nullptr, map_size, PROT_READ | PROT_WRITE,
MAP_SHARED,
fd,
file_offset);
if (unlikely(ptr == MAP_FAILED)) {
*base = nullptr;
return;
}
*base = reinterpret_cast<char*>(ptr);
}
void UnMapRegion(char* base) {
munmap(base, map_size);
}
void writer(int index) {
std::string fname = "data" + std::to_string(index);
std::string batch = "batch" + std::to_string(index);
char* base = nullptr;
char* cursor = nullptr;
uint64_t mmap_offset = 0, file_offset = 0;
int data_fd = ::open(fname.c_str(), O_RDWR | O_CREAT | O_DIRECT, 0645);
int batch_fd = ::open(batch.c_str(), O_RDWR | O_CREAT | O_DIRECT, 0645);
posix_fallocate(data_fd, 0, (4096UL * 1000000));
posix_fallocate(batch_fd, 0, map_size);
MapRegion(batch_fd, 0, &base);
if (unlikely(base == nullptr)) {
return;
}
cursor = base;
file_offset += map_size;
for (int32_t i = 0; i < 1000000; i++) {
if (unlikely(mmap_offset >= map_size)) {
pwrite64(data_fd, base, map_size, file_offset);
cursor = base;
file_offset += map_size;
mmap_offset = 0;
}
memcpy(cursor, data, 4096);
cursor += 4096;
mmap_offset += 4096;
}
UnMapRegion(base);
close(data_fd);
close(batch_fd);
}使用 vmstat 来获取写入速度的数据, 整理如下:
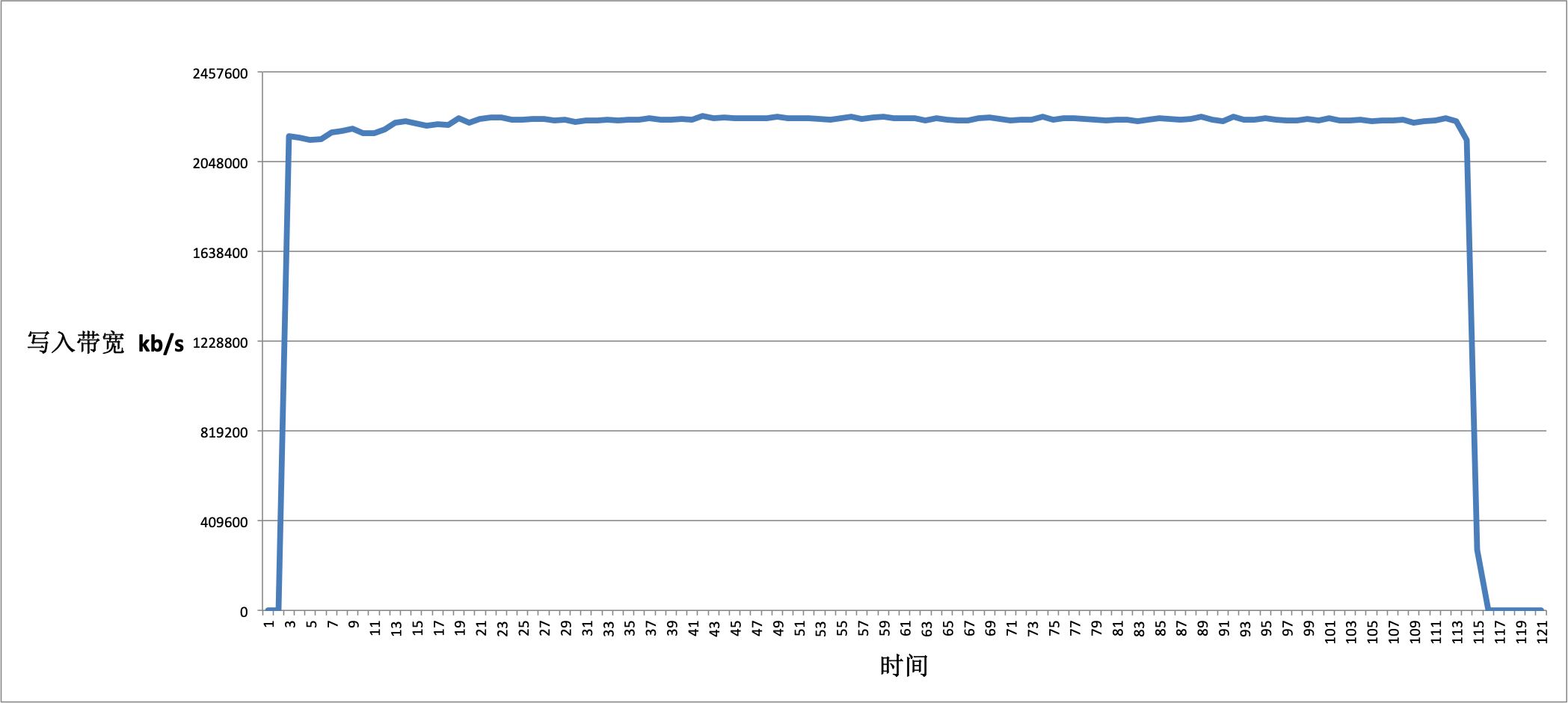
这次避免了 mmap() 的开销,写入速度可以稳定保持在 2180 MB/S 左右,且没有 I/O 抖动.
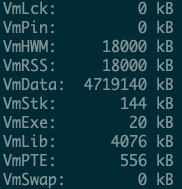
内存使用也仅仅只有 18000KB, 大约 18M:
结论:
下面是四种方式的写入速度对比:
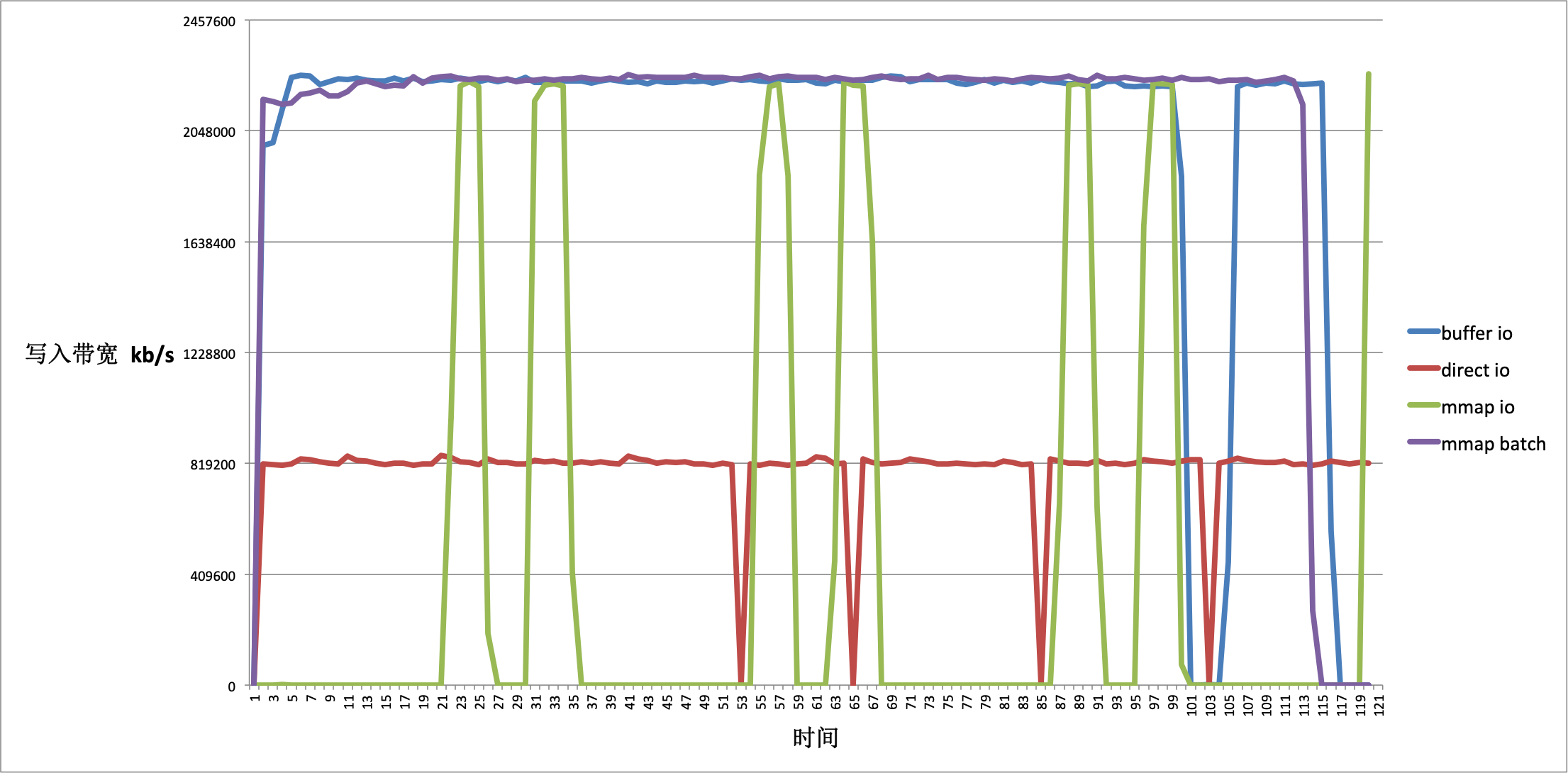 在限制内存,且需要
在限制内存,且需要 kill -9 不丢数据的情况下,我们可以使用 mmap() 来模拟 Buffer IO,但为了避免频繁 mmap() 的造成的 Page Fault 开销,我们需要一个临时文件来做我们的内存映射. 这种方法可以保证我们的写入速度稳定且 kill -9 不至于丢失数据.