DuckDB 查询执行器架构解析
引言
DuckDB 的执行器采用了 Push-based Vectorized Execution Model, 与传统的 Pull-based 模型相比, Push 模型在并行化,内存效率都有着显著优势.
传统的执行模型火山模型 (Volcano Pull Model) 存在缓存局部性差、并行度低的问题,其中最为关键的是算子内部缺乏水平并行能力;若想让多个线程同时处理同一算子的不同数据分片,需要借助 EXCHANGE 等算子复制工作管道。至于垂直并行,Volcano 模型本身就采用“上游拉取下游”方式串接算子,这一层面并不是瓶颈。
这在目前的单机多核的趋势下存在很大的性能问题, 关于 Pull-based vs Push-based, Volcano vs Pipeline 网上有大量的资料讨论过这个问题:
- Push-Based Execution in DuckDB
- Push vs. Pull-Based Loop Fusion in Query Engines
- What’s the difference between Clickhouse’s pipeline execution and Volcano model?
- OLAP 任务的并发执行与调度
- pipeline执行引擎以及一些工程优化
- 从 Volcano 火山模型到 Pipeline 执行模型, Apache Doris 执行模型的迭代
- Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age
DuckDB 的整个执行器都围绕着 Pipeline 的模型来设计, Pipeline 提供了结构化的并行理念, 将复杂的算子抽象成一个 DAG 有向无环图, 在整个 DAG 任务流中根据依赖关系可以将复杂的查询拆分为多个 Pipeline, 互不依赖的 Pipeline 可以并行执行.
DuckDB 采用 Morsel-Driven Parallelism 并行模型, 将数据划分为小的 “morsels”, 然后动态地将这些 morsels 分配给工作线程, 实现自适应的任务调度和更好的负载均衡. 这种机制解决了传统并行执行中的负载均衡问题, 特别是在处理数据倾斜的情况下能够动态调整任务分配.
执行器
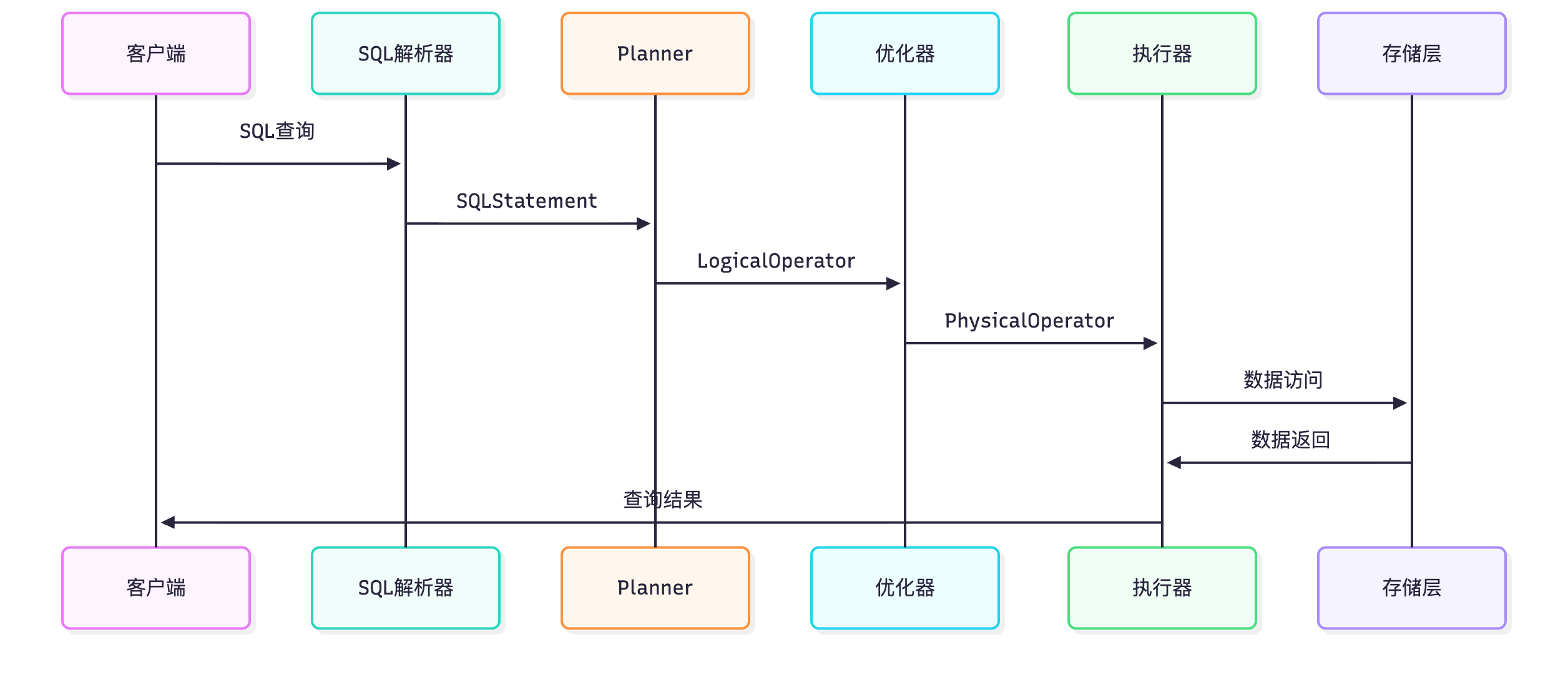
在之前的文章DuckDB 源码分析 - Logical Plan 逻辑计划我们介绍了 DuckDB 的逻辑计划, 逻辑计划转换为物理计划后经过执行器被转换为高效的并行执行 Pipeline.
执行器核心抽象与数据结构
逻辑计划构建完成以后进行物理计划的构建, 然后我们根据物理计划开始构建整个执行任务流. 物理计划生成的核心组件包括物理计划生成器 (PhysicalPlanGenerator), 物理操作符 (PhysicalOperator) 和物理计划 (PhysicalPlan). 这些组件协同工作, 将逻辑计划转换为可执行的物理计划.
/* src/main/client_context.cpp */
shared_ptr<PreparedStatementData>
ClientContext::CreatePreparedStatementInternal(ClientContextLock &lock, const string &query,
unique_ptr<SQLStatement> statement,
optional_ptr<case_insensitive_map_t<BoundParameterData>> values) {
/* ... */
if (config.enable_optimizer && logical_plan->RequireOptimizer()) {
profiler.StartPhase(MetricsType::ALL_OPTIMIZERS);
/* 进行逻辑计划的优化. */
Optimizer optimizer(*logical_planner.binder, *this);
logical_plan = optimizer.Optimize(std::move(logical_plan));
D_ASSERT(logical_plan);
profiler.EndPhase();
#ifdef DEBUG
logical_plan->Verify(*this);
#endif
}
/* 将逻辑计划转为物理计划. */
profiler.StartPhase(MetricsType::PHYSICAL_PLANNER);
PhysicalPlanGenerator physical_planner(*this);
result->physical_plan = physical_planner.Plan(std::move(logical_plan));
profiler.EndPhase();
D_ASSERT(result->physical_plan);
return result;
}
Pipeline 流水线机制
基本概念
-
执行模型: DuckDB 采用向量化 (DataChunk 为单位)的流水线执行. 每条 Pipeline 由 “一个 Source + 若干个中间 PhysicalOperator + 一个 Sink” 构成.
-
数据流向: Source 产出数据块 -> 中间算子按批变换 -> Sink 消费并汇总/产出最终结果或中间结果 (如哈希表).
-
调度体系: Pipeline 被拆分为可并行的任务, 由任务调度器在多线程环境下执行; PipelineExecutor 负责在本地线程上驱动这条管道.
-
MetaPipeline
MetaPipeline 是 “pipeline 的编排组合”, 定义 pipeline 的元数据,参数,依赖关系. 围绕同一个 Sink, 把多个以不同 Source 开始但共享同一 Sink 的 Pipeline 组织成一组, 并在组内与组间管理依赖与完成事件. MetaPipeline 还负责管理 Pipeline 之间的执行顺序和复杂依赖关系, 特别是在处理 Join 策略时协调 Build 侧和 Probe 侧的执行.
- Pipeline
一连串的物理计划操作符被切割成可并行,可调度的执行单元, 这个执行单元就是 pipeline. 明确一条从 Source 到 Sink 的线性数据流, 中间是一串可融合的算子.
一般情况下,MetaPipeline 围绕同一个 Sink 组织执行,通常只有一个基础 Pipeline (base pipeline)。多数算子(Projection/Filter/TableScan 等中间或 Source 算子)不会在该 MetaPipeline 下再生成额外 Pipeline。 但是也有例外,比如 Join 算子。
PhysicalOperator: 物理算子
Source: 源端算子, 作为整个 pipeline 的起点, 每个算子具体是 Source 算子还是 Sink 算子是初始化定义的, 比如 PhysicalTableScan 就是 Source 算子.
Sink: Pipeline Breaker 的算子.
有的算子即是 Source 算子, 也是 Sink 算子. 这类算子被称为 Pipeline Breaker, 它们会将一个 Pipeline 分割成多个独立的 Pipeline. 典型的 Pipeline Breaker 包括 Hash Join,Aggregation 等需要分阶段执行的算子.
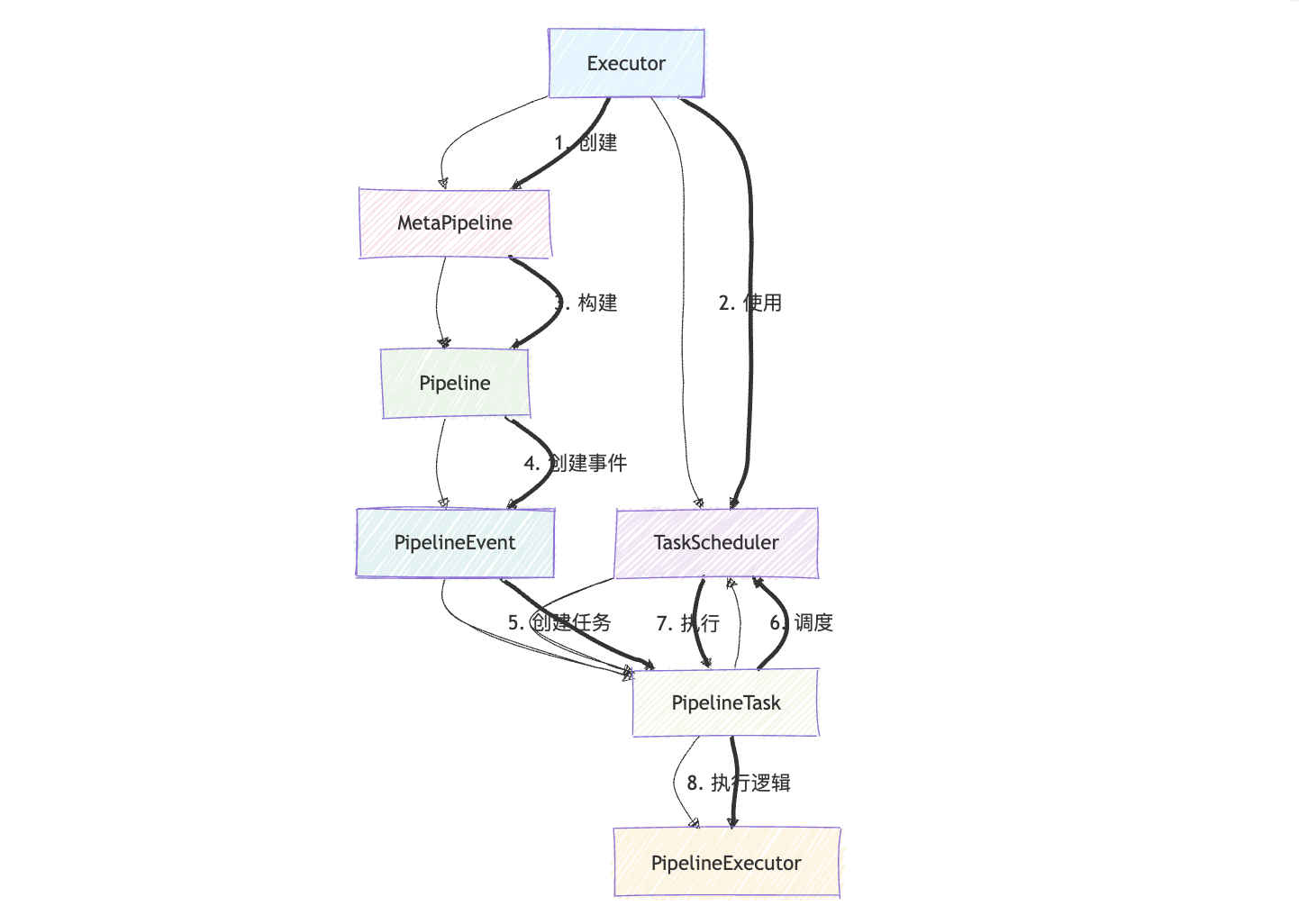
Pipeline 构建
调度过程由 Pipeline 和 PipelineExecutor 管理. 一个查询可能被划分为多个相互依赖的 Pipeline. PipelineExecutor 负责协调这些流水线的执行.
在 DuckDB 中,每一个查询语句都会被包装成以 PhysicalResultCollector 作为 root (顶层 Sink) 的物理计划,PhysicalResultCollector::GetResultCollector 会选择具体的 Collector 变体并作为 root operator 交给执行器初始化。
void Executor::InitializeInternal(PhysicalOperator &plan) {
/* 从当前 ClientContext 获取全局的任务调度器. */
auto &scheduler = TaskScheduler::GetScheduler(context);
{
lock_guard<mutex> elock(executor_lock);
physical_plan = &plan;
this->profiler = ClientData::Get(context).profiler;
profiler->Initialize(plan);
this->producer = scheduler.CreateProducer();
/* 构建所有的 pipelines. */
PipelineBuildState state;
/* 从 root 的 MetaPipeline 开始. */
auto root_pipeline = make_shared_ptr<MetaPipeline>(*this, state, nullptr);
/* 调用 Build 从物理计划根节点递归构建所有相关的 Pipeline, 并按 Pipeline 构建原则建立 Pipeline Breaker 与依赖. */
root_pipeline->Build(*physical_plan);
/* 调用 Ready 为所有 pipelines 生成并准备事件序列 (initialize -> event -> prepare finish -> finish -> complete),
* 使它们可被调度执行. */
root_pipeline->Ready();
/* ... */
// set root pipelines, i.e., all pipelines that end in the final sink
root_pipeline->GetPipelines(root_pipelines, false);
root_pipeline_idx = 0;
// collect all meta-pipelines from the root pipeline
/* 收集所有待调度的 MetaPipeline (递归搜索). */
vector<shared_ptr<MetaPipeline>> to_schedule;
root_pipeline->GetMetaPipelines(to_schedule, true, true);
// number of 'PipelineCompleteEvent's is equal to the number of meta pipelines, so we have to set it here
total_pipelines = to_schedule.size();
// collect all pipelines from the root pipelines (recursively) for the progress bar and verify them
root_pipeline->GetPipelines(pipelines, true);
// finally, verify and schedule
VerifyPipelines();
ScheduleEvents(to_schedule);
}
}我们构建一个样例数据, 使用 EXPLAIN 来理解物理计划如何转换成 pipelines 集合的:
-- 建表与数据
CREATE TABLE products(id INTEGER, category VARCHAR);
INSERT INTO products VALUES (1, 'A'), (2, 'B'), (3, 'C');
CREATE TABLE sales(product_id INTEGER, amount DOUBLE, sale_date DATE);
INSERT INTO sales VALUES
(1, 10.0, DATE '2024-01-10'),
(1, 20.0, DATE '2023-12-31'),
(2, 30.0, DATE '2024-06-15'),
(3, 40.0, DATE '2024-07-01'),
(2, 5.0, DATE '2025-01-01');
-- 查询
SELECT p.category, SUM(s.amount) AS total
FROM sales s
JOIN products p ON s.product_id = p.id
WHERE p.category IN ('A','B')
AND s.sale_date BETWEEN DATE '2024-01-01' AND DATE '2024-12-31'
GROUP BY p.category
ORDER BY total DESC
LIMIT 10;下图是 PhysicalOperator 描述的物理计划:
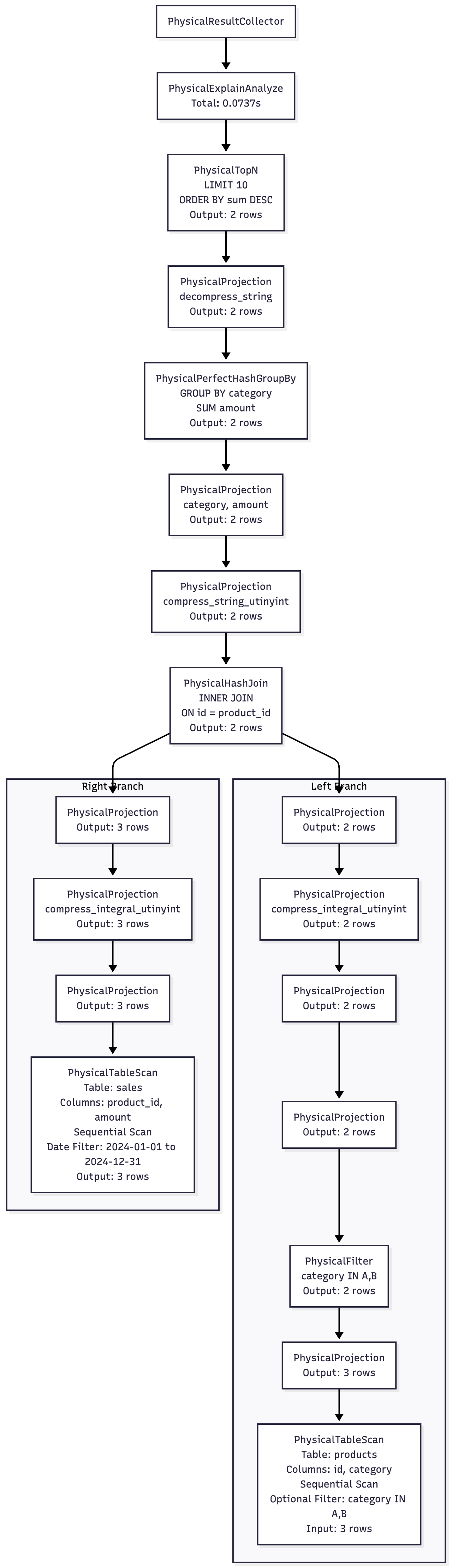
-
入口: PhysicalResultCollector
PhysicalResultCollector 是 Sink 操作符, 负责收集查询结果.
void PhysicalResultCollector::BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline) {
/* 1. 重置为 sink 状态. */
sink_state.reset();
/* 2. ResultCollector 没有直接子节点, 通过 plan 字段引用(PhysicalOperator &plan). */
D_ASSERT(children.empty());
/* 3. 将自己设置为当前 pipeline 的 Sink. */
auto &state = meta_pipeline.GetState();
state.SetPipelineSink(current, *this);
/* 4. 创建子 MetaPipeline 来构建实际的查询计划. */
auto &child_meta_pipeline = meta_pipeline.CreateChildMetaPipeline(current, *this);
child_meta_pipeline.Build(plan); /* plan = PhysicalExplainAnalyze. */
}-
PhysicalExplainAnalyze 操作符
PhysicalExplainAnalyze 使用默认的 BuildPipelines() 逻辑:
void PhysicalOperator::BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline) {
op_state.reset();
auto &state = meta_pipeline.GetState();
/* ... */
if (IsSink()) {
/* 1. PhysicalExplainAnalyze 既是 Sink 操作符也是 Source 操作符. */
sink_state.reset();
/* 2. 将自己设置为当前 Pipeline 的 Source. */
state.SetPipelineSource(current, *this);
/* 3. 创建一个新的 MetaPipeline 来递归子操作符. */
auto &child_meta_pipeline = meta_pipeline.CreateChildMetaPipeline(current, *this);
child_meta_pipeline.Build(children[0].get());
return;
}
/* ... */
}-
PhysicalTopN 操作符
PhysicalTopN 既是 Source 又是 Sink,也使用默认的 BuildPipelines() 逻辑:
-
PhysicalProjection 操作符
PhysicalProjection 既不是 Sink 也不是 Source,但是也使用默认的 BuildPipelines() 逻辑:
void PhysicalOperator::BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline) {
op_state.reset();
/* Projection 不是Sink, 不是Source, 有子节点. */
auto &state = meta_pipeline.GetState();
/* ... */
/* 添加到当前 pipeline ( pipeline.operators.push_back(op)) 并递归. */
state.AddPipelineOperator(current, *this);
children[0].get().BuildPipelines(current, meta_pipeline); /* 调用 PhysicalPerfectHashGroupBy 继续构建 pipeline. */
}-
PhysicalPerfectHashAggregate 操作符
PhysicalPerfectHashAggregate 既是 Sink 也是 Source,使用默认的 BuildPipelines() 逻辑:
从 PhysicalPerfectHashAggregate 下来有连续两个 PhysicalProjection 操作符, 然后来到了 Hash Join 操作符.
-
PhysicalHashJoin 操作符
PhysicalHashJoin 是一个比较复杂的操作符, 它会创建 Build 侧和 Probe 侧两个不同的 Pipeline:
//===--------------------------------------------------------------------===//
// Pipeline Construction
//===--------------------------------------------------------------------===//
void PhysicalJoin::BuildJoinPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline, PhysicalOperator &op,
bool build_rhs) {
op.op_state.reset();
op.sink_state.reset();
/* 把 Join 操作符加入当前 pipeline. */
auto &state = meta_pipeline.GetState();
state.AddPipelineOperator(current, op);
vector<shared_ptr<Pipeline>> pipelines_so_far;
meta_pipeline.GetPipelines(pipelines_so_far, false);
auto &last_pipeline = *pipelines_so_far.back();
vector<shared_ptr<Pipeline>> dependencies;
optional_ptr<MetaPipeline> last_child_ptr;
if (build_rhs) {
/* 构建右子树 (Build 侧) 的 MetaPipeline. */
// on the RHS (build side), we construct a child MetaPipeline with this operator as its sink
auto &child_meta_pipeline = meta_pipeline.CreateChildMetaPipeline(current, op, MetaPipelineType::JOIN_BUILD);
/* 根据 PhysicalOperator 递归构建右边的 pipelines. */
child_meta_pipeline.Build(op.children[1]);
if (op.children[1].get().CanSaturateThreads(current.GetClientContext())) {
// if the build side can saturate all available threads,
// we don't just make the LHS pipeline depend on the RHS, but recursively all LHS children too.
// this prevents breadth-first plan evaluation
/* 这个 if 判断是一个性能优化和执行顺序控制的关键逻辑.
* 如果 Build 阶段能占满所有可用线程, 要防止广度优先(breadth-first)的策略被先行执行,
* 也就是左子树所有的 pipelines 都要依赖右子树, 让 Build 阶段先完成再来调度左边的 Probe 阶段. */
child_meta_pipeline.GetPipelines(dependencies, false);
last_child_ptr = meta_pipeline.GetLastChild();
}
}
// continue building the current pipeline on the LHS (probe side)
/* 继续当前 MetaPipeline, 构建左子树 (Probe 侧) 的 pipelines. */
op.children[0].get().BuildPipelines(current, meta_pipeline);
if (last_child_ptr) {
// the pointer was set, set up the dependencies
/* 让左子树中所有后续创建的子 MetaPipeline 的所有 Pipeline, 都依赖于右表 Build 侧的所有 Pipeline. */
meta_pipeline.AddRecursiveDependencies(dependencies, *last_child_ptr);
}
/* 特殊 Join 类型处理. */
switch (op.type) {
case PhysicalOperatorType::POSITIONAL_JOIN:
// Positional joins are always outer
meta_pipeline.CreateChildPipeline(current, op, last_pipeline);
return;
case PhysicalOperatorType::CROSS_PRODUCT:
return;
default:
break;
}
// Join can become a source operator if it's RIGHT/OUTER, or if the hash join goes out-of-core
/* 某些 Join 操作会主动产生额外的输出数据 (Source角色), 所以需要创建一个额外的 Pipeline 来处理这些输出. */
if (op.Cast<PhysicalJoin>().IsSource()) {
meta_pipeline.CreateChildPipeline(current, op, last_pipeline);
}
}PhysicalHashJoin 算子会创建 Build 阶段和 Probe 阶段两个不同的 Pipeline:
- Build 阶段(右子树): 负责构建哈希表
- Probe 阶段(左子树): 负责探测哈希表
Build 阶段必须在 Probe 阶段之前完成, 两个阶段之间有明确的依赖关系. 这种设计确保了在探测哈希表之前, 哈希表已经完全构建完成.
- PhysicalTableScan 操作符
Join 操作符经过几个投影算子 + PhysicalFilter 算子以后就来到了 PhysicalTableScan 操作符, PhysicalTableScan 只是一个 Source 算子, 使用默认的 BuildPipelines() 逻辑:

这条 SQL 在当前物理计划下有 4 个 MetaPipelines:
1: ExplainAnalyze (顶层 Sink+Source, 用于统计与包装输出). 2: TopN (最终排序与限流的 Sink + Source, 承接聚合结果). 3: PerfectHashGroupBy (聚合 Sink, 承接 Join 后的数据). 4: HashJoin.
MetaPipelines 之间是存在依赖关系,依赖关系和构建顺序是相反的,父 MetaPipeline 依赖子 MetaPipeline,依赖关系的构建时机是在父 MetaPipeline 构建子 MetaPipeline 时确立:
MetaPipeline &MetaPipeline::CreateChildMetaPipeline(Pipeline ¤t, PhysicalOperator &op, MetaPipelineType type) {
children.push_back(make_shared_ptr<MetaPipeline>(executor, state, &op, type));
auto &child_meta_pipeline = *children.back().get();
// store the parent
child_meta_pipeline.parent = ¤t;
// child MetaPipeline must finish completely before this MetaPipeline can start
/* 当前的 pipeline 依赖子 MetaPipeline 的 base pipeline 完成. */
current.AddDependency(child_meta_pipeline.GetBasePipeline());
// child meta pipeline is part of the recursive CTE too
child_meta_pipeline.recursive_cte = recursive_cte;
return child_meta_pipeline;
}Pipeline 任务调度和执行
从 PhysicalTableScan 开始, Source 算子每次产出一批数据, 单位就是 DataChunk, 中间算子按批消费/产生 DataChunk. Sink 算子消费 DataChunk, 如果它同时充当 Source 时, 再以 DataChunk 形式向下游提供结果.
在构建完成 Pipelines 流以后, DuckDB 开始进入 Pipelines 的执行流程:
void Executor::InitializeInternal(PhysicalOperator &plan) {
/* 从当前 ClientContext 获取全局的任务调度器. */
auto &scheduler = TaskScheduler::GetScheduler(context);
{
lock_guard<mutex> elock(executor_lock);
physical_plan = &plan;
this->profiler = ClientData::Get(context).profiler;
profiler->Initialize(plan);
this->producer = scheduler.CreateProducer();
/* 构建所有的 pipelines. */
PipelineBuildState state;
/* 从 root 的 MetaPipeline 开始. */
auto root_pipeline = make_shared_ptr<MetaPipeline>(*this, state, nullptr);
/* 调用 Build 从物理计划根节点递归构建所有相关的 Pipeline,并按 Pipeline 构建原则建立 Pipeline Breaker 与依赖关系. */
root_pipeline->Build(*physical_plan);
/* 整个 MetaPipeline 树上的所有 Pipeline 切换到 "可执行态", 并将每条 Pipeline 的算子链调整为执行所需的顺序. */
root_pipeline->Ready();
/* ... */
// set root pipelines, i.e., all pipelines that end in the final sink
root_pipeline->GetPipelines(root_pipelines, false);
root_pipeline_idx = 0;
// collect all meta-pipelines from the root pipeline
/* 收集所有待调度的 MetaPipeline (递归搜索). */
vector<shared_ptr<MetaPipeline>> to_schedule;
root_pipeline->GetMetaPipelines(to_schedule, true, true);
// number of 'PipelineCompleteEvent's is equal to the number of meta pipelines, so we have to set it here
total_pipelines = to_schedule.size();
// collect all pipelines from the root pipelines (recursively) for the progress bar and verify them
/* 收集所有待调度的 pipelines (递归搜索). */
root_pipeline->GetPipelines(pipelines, true);
// finally, verify and schedule
VerifyPipelines();
/* 为所有 MetaPipeline 及其内的 Pipeline 构建 "事件调度栈" (Event Stack). */
ScheduleEvents(to_schedule);
}
}DuckDB 采用一个事件驱动的模型来完成 Pipeline 的执行, Pipeline Event 和 PipelineTask 是两个核心组件, 它们协同工作来实现高效的查询执行.
一个 Pipeline 对应多个 Event:
- PipelineInitializeEvent: 负责初始化 Pipeline
- PipelineEvent: 负责调度 Pipeline 的主要执行任务
- PipelinePrepareFinishEvent: 负责准备完成阶段
- PipelineFinishEvent: 负责完成阶段
- PipelineCompleteEvent: 负责整个 Pipeline 的完成
ScheduleEvents() 是将构建完成的 Pipelines 转换为事件驱动执行的核心函数, 每条 Pipeline 都会生成一个事件栈 (关于 PipelineEvent 的一个组合), 依赖关系是:
// dependencies: initialize -> event -> prepare finish -> finish -> complete
base_stack.pipeline_event.AddDependency(base_stack.pipeline_initialize_event);
base_stack.pipeline_prepare_finish_event.AddDependency(base_stack.pipeline_event);
base_stack.pipeline_finish_event.AddDependency(base_stack.pipeline_prepare_finish_event);
base_stack.pipeline_complete_event.AddDependency(base_stack.pipeline_finish_event);每个 PipelineEvent 通过以下流程创建 PipelineTask:
- 调用 PipelineEvent::Schedule() 方法
- 调用 Pipeline::Schedule() 方法
- 判断是否可以并行执行:
- 如果可以并行, 则调用 LaunchScanTasks() 创建多个 PipelineTask
- 如果不能并行, 则调用 ScheduleSequentialTask() 创建单个 PipelineTask
- 通过 event->SetTasks() 将创建的PipelineTask提交给TaskScheduler
因为有一部分算子其实是可以并行执行的, 所以 Pipeline 和 PipelineTask 并不是完全一一对应的关系, 一个 Pipeline 可以根据估算拆分多个 PipelineTask 并行执行:
比如 PhysicalTableScan 算子所在的 Pipeline:
Pipeline (扫描大表)
├── Source: PhysicalTableScan (估算4个并行分片)
├── Operators: [...]
└── Sink: [...]
执行时分解为:
PipelineTask-1 (处理分片1)
PipelineTask-2 (处理分片2)
PipelineTask-3 (处理分片3)
PipelineTask-4 (处理分片4)- 一个 Pipeline 可以对应多个 PipelineTask.
- 共享内容: PipelineTask 共享同一条 Pipeline 的算子链和必要的全局状态,但每个任务都会维护独立的本地 Source/Operator/Sink 状态。
PipelineTask 的执行:
- PipelineTask 继承自 ExecutorTask, 负责实际执行 Pipeline 工作
- 创建PipelineExecutor: 每个 PipelineTask 会创建一个 PipelineExecutor 实例
- 执行Pipeline: 调用 PipelineExecutor 执行具体的查询逻辑
- 执行完成后调用 event->FinishTask() 通知 PipelineEvent
Pipeline 并行执行
我们已经探讨了 Pipeline 的整个生成流程,了解了 Pipeline 如何被分解为多个 PipelineTask,并通过 PipelineEvent 进行调度管理。这些 PipelineTask 最终由 DuckDB 的 TaskScheduler 来真正执行。
DuckDB 在启动时创建一个全局的 TaskScheduler, 创建的 Worker 数量是参数决定的:
scheduler->SetThreads(config.options.maximum_threads, config.options.external_threads);
scheduler->RelaunchThreads();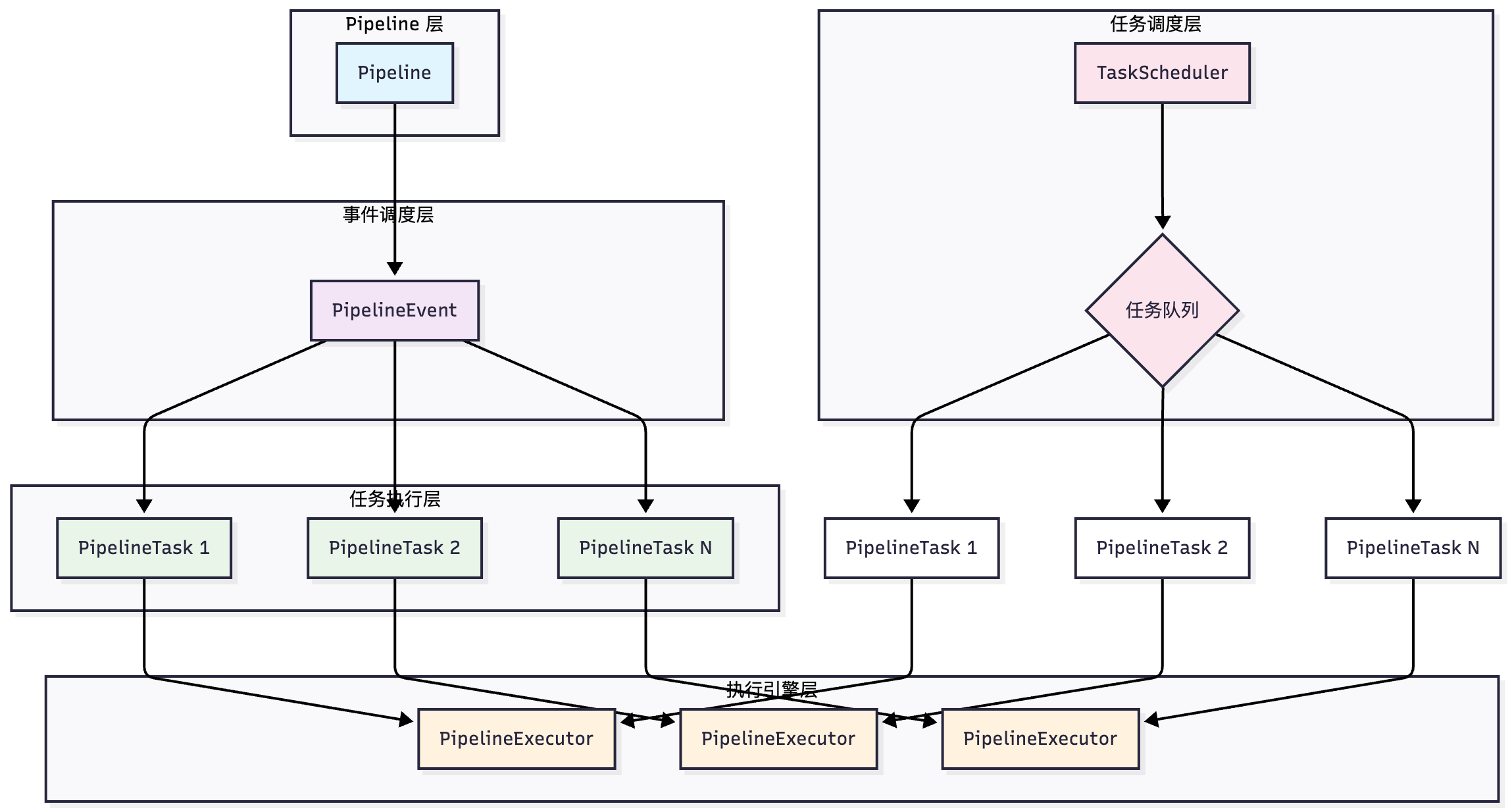
每个 Worker 线程调度函数 TaskScheduler::ExecuteForever() 处理全局任务队列中的任务, 任务队列是一个 multi-producer, multi-consumer 线程安全的无锁队列.
需要注意的是使用一个 multi-producer, multi-consumer 线程安全的无锁队列, 多个工作线程可以从同一个队列中获取任务, 所以这里隐含了负载均衡.
void TaskScheduler::ExecuteForever(atomic<bool> *marker) {
#ifndef DUCKDB_NO_THREADS
static constexpr const int64_t INITIAL_FLUSH_WAIT = 500000; // initial wait time of 0.5s (in mus) before flushing
auto &config = DBConfig::GetConfig(db);
shared_ptr<Task> task;
/* 线程主循环. */
while (*marker) {
/* ... */
if (queue->Dequeue(task)) {
/* 从无锁任务队列中获取任务. */
auto process_mode = config.options.scheduler_process_partial ? TaskExecutionMode::PROCESS_PARTIAL
: TaskExecutionMode::PROCESS_ALL;
/* 执行任务. */
auto execute_result = task->Execute(process_mode);
/* 根据执行结果处理任务. */
switch (execute_result) {
case TaskExecutionResult::TASK_FINISHED:
case TaskExecutionResult::TASK_ERROR:
task.reset(); /* 任务完成, 释放资源. */
break;
case TaskExecutionResult::TASK_NOT_FINISHED: {
/* 任务未完成, 重新入队. */
auto &token = *task->token;
queue->Enqueue(token, std::move(task));
break;
}
case TaskExecutionResult::TASK_BLOCKED:
/* 任务被阻塞, 取消调度. */
task->Deschedule();
task.reset();
break;
}
} else if (queue->GetTasksInQueue() > 0) {
// failed to dequeue but there are still tasks remaining - signal again to retry
queue->semaphore.signal(1);
}
}
/* ... */
}Pipeline 执行的核心函数是 PipelineExecutor::Execute(), 负责驱动数据从源到终点的完整流程:
PipelineExecuteResult PipelineExecutor::Execute(idx_t max_chunks) {
/* 确保当前 Pipeline 具有 Sink (数据接收端). */
D_ASSERT(pipeline.sink);
/* 获取源数据, 如果这个 Pipeline 没有中间操作符, 直接使用 final_chunk,
* 否则使用第一个中间数据块 intermediate_chunks[0]. */
auto &source_chunk = pipeline.operators.empty() ? final_chunk : *intermediate_chunks[0];
/* ExecutionBudget 用来限制单次调用 Execute() 最多处理多少个 Chunk 的数据, 超过以后会结束这轮任务. */
ExecutionBudget chunk_budget(max_chunks);
/* 主执行循环. */
do {
/* 检查客户端是否已中断. */
if (context.client.interrupted) {
throw InterruptException();
}
/* 根据不同状态选择执行路径, 这些状态符 (exhausted_source, done_flushing..) 初始化都是 false. */
OperatorResultType result;
if (exhausted_source && done_flushing && !remaining_sink_chunk && !next_batch_blocked &&
in_process_operators.empty()) {
/* 所有条件都满足, 退出循环. */
break;
} else if (remaining_sink_chunk) {
// The pipeline was interrupted by the Sink. We should retry sinking the final chunk.
/* Sink 操作符之前是被阻塞的, 重新尝试将最终数据块推送到 Sink. */
result = ExecutePushInternal(final_chunk, chunk_budget);
D_ASSERT(result != OperatorResultType::HAVE_MORE_OUTPUT);
remaining_sink_chunk = false;
} else if (!in_process_operators.empty() && !started_flushing) {
// Operator(s) in the pipeline have returned `HAVE_MORE_OUTPUT` in the last Execute call
// the operators have to be called with the same input chunk to produce the rest of the output
/* PhysicalOperator 在上次执行中返回了 HAVE_MORE_OUTPUT, 需要再次调用这个操作符产生剩下的输出结果. */
D_ASSERT(source_chunk.size() > 0);
result = ExecutePushInternal(source_chunk, chunk_budget);
} else if (exhausted_source && !next_batch_blocked && !done_flushing) {
// The source was exhausted, try flushing all operators
/* 数据源已消费完, 尝试刷新支持缓存的操作符. */
auto flush_completed = TryFlushCachingOperators(chunk_budget);
if (flush_completed) {
done_flushing = true;
break;
} else {
if (remaining_sink_chunk) {
return PipelineExecuteResult::INTERRUPTED;
} else {
D_ASSERT(chunk_budget.IsDepleted());
return PipelineExecuteResult::NOT_FINISHED;
}
}
} else if (!exhausted_source || next_batch_blocked) {
/* 通过 Pipeline 的 Source PhysicalOperator 获取新数据并处理. */
SourceResultType source_result;
if (!next_batch_blocked) {
// "Regular" path: fetch a chunk from the source and push it through the pipeline
source_chunk.Reset();
source_result = FetchFromSource(source_chunk);
if (source_result == SourceResultType::BLOCKED) {
/* 如果数据源被阻塞, 返回中断状态. */
return PipelineExecuteResult::INTERRUPTED;
}
/* 如果数据源已经消费完成, 标记 FINISHED. */
if (source_result == SourceResultType::FINISHED) {
exhausted_source = true;
}
}
if (required_partition_info.AnyRequired()) {
auto next_batch_result = NextBatch(source_chunk);
next_batch_blocked = next_batch_result == SinkNextBatchType::BLOCKED;
if (next_batch_blocked) {
return PipelineExecuteResult::INTERRUPTED;
}
}
if (exhausted_source && source_chunk.size() == 0) {
// To ensure that we're not early-terminating the pipeline
continue;
}
/* 将数据块推送到 Pipeline 中的 PhysicalOperator 处理. */
result = ExecutePushInternal(source_chunk, chunk_budget);
} else {
throw InternalException("Unexpected state reached in pipeline executor");
}
if (result == OperatorResultType::BLOCKED) {
/* 处理 Sink 操作中断, 如果 Sink 操作符被阻塞, 设置 remaining_sink_chunk = true, 返回中断状态. */
remaining_sink_chunk = true;
return PipelineExecuteResult::INTERRUPTED;
}
if (result == OperatorResultType::FINISHED) {
/* 整个 Pipeline 已经处理完成, 直接返回. */
break;
}
} while (chunk_budget.Next());
/* 检查 Pipeline 是否完成:
* 1. Source 数据尚未被完全消费.
* 2. 缓存操作符的刷新操作没有执行.
* 3. 整个 Pipeline 还没有完成. */
if ((!exhausted_source || !done_flushing) && !IsFinished()) {
return PipelineExecuteResult::NOT_FINISHED;
}
/* 整个 Pipeline 已经完成, 执行最终化操作. */
return PushFinalize();
}用户的主线程在将查询分解成多个 PipelineTask 下发给 TaskScheduler 后, 并不会陷入空闲等待状态, 而是负责监控整个查询任务的执行过程 PendingQueryResult::ExecuteInternal(), 其中除了任务过程中的异常处理和协调任务完成的获取查询结果 (ClientContext::FetchResultInternal()), 主线程也会择机选择 TaskScheduler 中属于自身查询的 Task 来执行.
总结
DuckDB 的执行器概念和细节繁多,但是 DuckDB 的开发者将整个执行流程进行了清晰的抽象,各个模块互相交互又不至于耦合过深,这体现了非常优秀的架构设计能力。学习 DuckDB 的代码设计,不仅仅是为了理解执行器的整个流程,对于系统工程师来说学习这种设计理念更为重要:
-
流水线的并行化:在系统架构中,Worker Pool 是一个常见的设计,但是大部分的 Worker Pool 都是以 Task 为运行粒度,Task 内部并不会再次拆分,这一方面无法利用多核处理器,在内存方面需要一次性加载所有的数据。DuckDB 将一个 Task 抽象成完全的流水线,在处理一个复杂的 SQL 时,比如多表连接,将其进一步拆分成多个小任务,使用 DAG 来组织任务,整个处理过程就变得清晰可控。拆分成流水线以后,DuckDB 还能将复杂的算子,比如一个 SCAN 操作进行并行的处理。
-
负载均衡:DuckDB 使用无锁队列直接就解决了任务分配的负载问题,共享队列模型本质上避免了 stealing 的需要,并且整个调度器的线程数量也可以动态的根据负载进行调整,尽可能的充分利用计算资源。
-
精细的任务控制:DuckDB 支持将小任务进行更精细化的拆分:
enum class TaskExecutionMode : uint8_t {
PROCESS_ALL, /* 完全执行任务。 */
PROCESS_PARTIAL /* 部分执行任务。 */
};DuckDB 通过 scheduler_process_partial 配置选项来控制默认的执行模式,默认情况下,这个选项是 false,但在某些验证模式下可以设置为 true。在大多数场景下,DuckDB 的 TaskScheduler 都是使用 PROCESS_ALL 模式,但是主线程(用户线程)是使用 PROCESS_PARTIAL,如果使用了 PROCESS_PARTIAL mode,通过 ExecutionBudget 会限制每批处理的 Chunk 数量,主线程还有协调任务和监控异常的额外工作,所以长期陷入任务执行是不友好的设计。
- 依赖关系的处理:DuckDB 引入了 MetaPipeline 的概念,代表一组具有相同 Sink 的流水线,这种设计允许更精细地管理复杂查询中多个流水线之间的依赖关系。流水线内部依赖:同一 MetaPipeline 内不同流水线之间的依赖,流水线间依赖:不同 MetaPipeline 之间的依赖,特殊操作符依赖:如 Join 操作的构建侧和探测侧之间的依赖。整个依赖体系层层递进,实现较为优雅.